 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong thế giới của AI và Machine Learning, một mô hình sẽ không bao giờ thông minh hơn dữ liệu mà nó được huấn luyện. Tuy nhiên, không phải lúc nào chúng ta cũng có được dữ liệu sạch và hoàn hảo. Các nguồn dữ liệu thường đa dạng, vậy làm thế nào để mô hình của bạn có thể phân biệt được đâu là thông tin đáng tin cậy để đưa ra quyết định đúng đắn?
Để ưu tiên một nguồn, chúng ta cần gán cho nó một giá trị, thường gọi là trọng số. Trọng số này có thể là một số float từ 0.0 đến 1.0, hoặc một giá trị định danh. Tùy thuộc vào dự án, bạn có thể chọn cách phù hợp nhất.
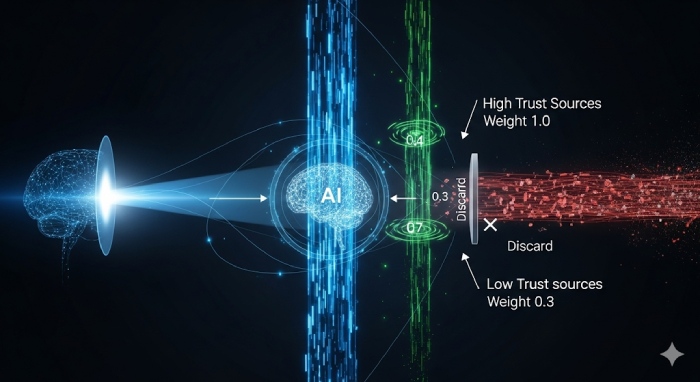
Sau khi đã phân loại và gán trọng số, bạn sẽ lập trình để mô hình biết cách ưu tiên. Có vài cách phổ biến như phương pháp Chain of Responsibility: Đây là cách đơn giản và phổ biến nhất. Khi cần một thông tin, bạn sẽ tạo một chuỗi tìm kiếm theo thứ tự ưu tiên. Ví dụ:
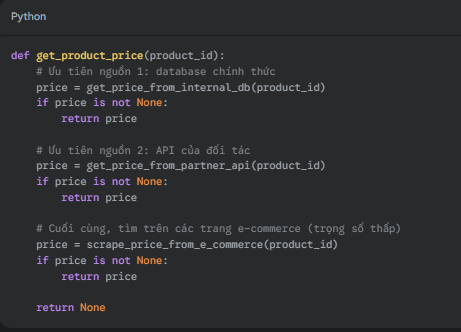
def get_product_price(product_id):
# Ưu tiên nguồn 1: database chính thức
price = get_price_from_internal_db(product_id)
if price is not None:
return price
# Ưu tiên nguồn 2: API của đối tác
price = get_price_from_partner_api(product_id)
if price is not None:
return price
# Cuối cùng, tìm trên các trang e-commerce (trọng số thấp)
price = scrape_price_from_e_commerce(product_id)
if price is not None:
return price
return None
Với cách này, khi tìm thấy kết quả từ nguồn tin cậy nhất, chương trình sẽ dừng lại ngay lập tức.
Sử dụng trung bình có trọng số là khi bạn cần tổng hợp thông tin từ nhiều nguồn để đưa ra một quyết định, cách này rất hiệu quả. Ví dụ, để xác định một giá trị cuối cùng. Công thức sẽ là:
Kết quả cuối cùng = (Giá_trị_nguồn_1 x Trọng_số_1) + (Giá_trị_nguồn_2 x Trọng_số_2) + …
Trong quá trình huấn luyện mô hình, bạn có thể lập trình để gán một loại phạt cho dữ liệu từ nguồn trọng số thấp. Nếu một thông tin từ nguồn trọng số thấp mâu thuẫn với một thông tin từ nguồn trọng số cao, bạn có thể tự động loại bỏ thông tin từ nguồn thấp đó.
Trong thực tế, nền tảng trợ lý ảo hiện đại Dịch vụ Chatbot AI của Vccorp cũng ứng dụng cơ chế gán trọng số dữ liệu. Ví dụ, khi tư vấn khách hàng, BizChatAI ưu tiên thông tin từ CRM hoặc CDP (đã kiểm duyệt nội bộ) hơn là dữ liệu nhập tự do. Điều này giúp câu trả lời chính xác và nhất quán hơn trong môi trường thực tế.
| Hiện tại, BizChatAI (VCCorp) đang mở dùng thử miễn phí loạt AI Agent theo ngành. Mời bạn chat thử ngay TẠI ĐÂY |
Việc ưu tiên và gán trọng số cho dữ liệu là một bước đi thông minh. Nó giúp bạn tối ưu tài nguyên, không phải tốn công sức làm sạch từng byte dữ liệu. Thay vào đó, bạn tập trung vào việc đảm bảo chất lượng của các nguồn dữ liệu cốt lõi từ đó giúp mô hình học được những điều đúng đắn.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
