 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong các hội thoại dài, mô hình ngôn ngữ lớn (LLM) thường gặp khó khăn khi xử lý thông tin nằm giữa đoạn văn, hiện tượng được gọi là Lost in the Middle. Bài viết này sẽ phân tích nguyên nhân, đồng thời giới thiệu kỹ thuật Re-ranking để sắp xếp lại dữ liệu trong context window, giúp cải thiện chất lượng phản hồi và trải nghiệm người dùng.
Mỗi mô hình ngôn ngữ lớn (LLM) đều có một "bộ nhớ ngắn hạn" được gọi là context window – nơi chứa toàn bộ thông tin của cuộc hội thoại hoặc văn bản trước khi đưa vào mô hình. Context window thường được tính bằng số lượng token, ví dụ: GPT-4 hỗ trợ khoảng 8k – 128k token tùy phiên bản.
Khi nội dung hội thoại ngắn (dưới 1k token), mô hình có thể xử lý dễ dàng. Nhưng khi văn bản lên đến hàng chục nghìn token, mô hình buộc phải phân bổ sự chú ý. Nó không thể “đọc” toàn bộ chi tiết như con người mà thường ưu tiên phần đầu và phần cuối. Hệ quả là các thông tin nằm ở giữa dễ bị bỏ quên.

Hiện tượng Lost in the Middle đã được chỉ ra rõ trong nhiều nghiên cứu. Cụ thể:

Ví dụ: Bạn nhập vào mô hình một báo cáo 30 trang rồi hỏi về số liệu tài chính ở trang 15. Nếu không có kỹ thuật bổ trợ, LLM có thể trả lời sai hoặc bỏ qua vì “không nhớ” đoạn đó. Đây chính là rủi ro khi triển khai AI cho nghiệp vụ thật như phân tích tài liệu pháp lý, báo cáo tài chính, hay CSKH đa kênh.
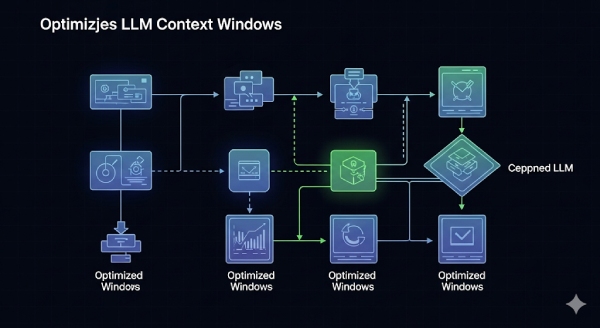
Thay vì nhồi tất cả dữ liệu vào context window, cách tốt hơn là chỉ chọn những đoạn liên quan nhất với truy vấn người dùng. Đây chính là vai trò của Re-ranking, bước đánh giá lại mức độ phù hợp của từng đoạn dữ liệu trước khi đưa vào context. Cơ chế cơ bản:
Nhờ vậy, thông tin quan trọng dù nằm ở giữa tài liệu cũng có cơ hội được ưu tiên đưa vào prompt, thay vì bị “chôn vùi” giữa đống dữ liệu ít liên quan.
Ngoài re-ranking, nhiều kỹ thuật khác cũng được áp dụng để tăng hiệu quả:
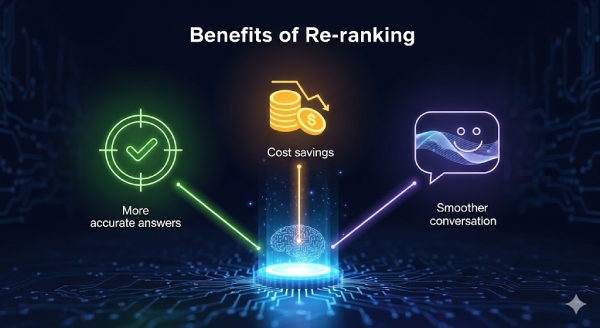
Việc áp dụng Re-ranking tuy tốn thêm chi phí tính toán (vì cần một mô hình đánh giá lại), nhưng mang lại lợi ích:
Do đó, đây là một trong những bước quan trọng để nâng tầm ứng dụng LLM từ mức demo sang sản phẩm thực tế.
Tóm lại, việc tối ưu context window cho hội thoại dài không chỉ là một cải tiến về mặt kỹ thuật, mà còn là một bước tiến quan trọng trong việc xây dựng các hệ thống tự động thông minh. Bằng cách tách biệt phần hiểu (NLU) chúng ta có thể tạo ra một kiến trúc linh hoạt, dễ mở rộng và bảo trì.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
