 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong các dự án AI hiện đại, dữ liệu là nhiên liệu quyết định hiệu suất mô hình. Tuy nhiên, khi dữ liệu quá lớn hoặc không đồng nhất, mô hình có thể khó học được các ngữ cảnh chính xác. Lúc này, kỹ thuật chunking đóng vai trò cực kỳ quan trọng. Bài viết này sẽ hướng dẫn bạn cách tích hợp chunking vào pipeline huấn luyện AI một cách tự động, giúp tối ưu hóa luồng xử lý dữ liệu, nâng cao tốc độ huấn luyện và độ chính xác tổng thể của mô hình.
Embedding là bước chuyển văn bản hoặc dữ liệu phi cấu trúc thành vector số học giúp mô hình AI hiểu và truy xuất thông tin theo ngữ nghĩa thay vì từ khóa. Tuy nhiên, vector chỉ phản ánh ngữ nghĩa tại thời điểm được tạo ra. Khi dữ liệu gốc thay đổi, ví dụ:

Tình huống này đặc biệt nghiêm trọng với hệ thống có hàng trăm nghìn hoặc hàng triệu vector, ví dụ hệ thống chăm sóc khách hàng tự động hoặc công cụ tìm kiếm nội bộ doanh nghiệp.
Để hiểu chiến lược cập nhật, bạn cần nắm được mối liên hệ giữa dữ liệu gốc và dữ liệu đã embedding trong Vector DB. Mỗi vector thường được lưu cùng metadata, gồm:
Ví dụ cấu trúc trong ChromaDB:
collection.add(
documents=["Nội dung về cập nhật embedding..."],
metadatas=[{"source": "blog", "version": 3}],
ids=["doc_123"]
)
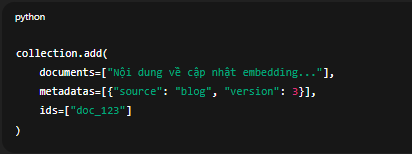
Chính nhờ id và metadata mà hệ thống có thể theo dõi và cập nhật chính xác vector liên quan mỗi khi dữ liệu gốc thay đổi.
Cách này khá thô sơ nhưng dễ hiểu: mỗi khi dữ liệu thay đổi, bạn xóa toàn bộ embedding cũ và tạo lại toàn bộ vector.
Ví dụ: Khi bạn có 5000 bài viết, thay đổi 5 bài → tái sinh embedding cho cả 5000 bài.
Ưu điểm:
Nhược điểm:
Phù hợp: Các hệ thống nhỏ, dữ liệu ít, hoặc cần tính đồng nhất cao (ví dụ: cơ sở tri thức chỉ vài nghìn tài liệu).
Đây là phương án phổ biến và tiết kiệm nhất. Thay vì tái tạo toàn bộ, hệ thống chỉ cập nhật những vector có thay đổi.
Cách triển khai:
Ví dụ với ChromaDB:
collection.delete(ids=["product_456"])
collection.add(
documents=["Mô tả sản phẩm mới sau cập nhật"],
ids=["product_456"]
)
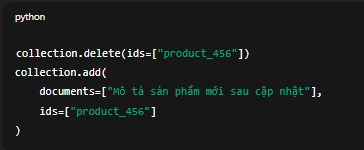
Ưu điểm:
Nhược điểm: Cần cơ chế phát hiện thay đổi chính xác.
Phù hợp: Các ứng dụng web, hệ thống CMS, eCommerce hoặc CRM có cập nhật dữ liệu theo thời gian thực.
Chiến lược này dành cho hệ thống cần kiểm soát lịch sử thay đổi embedding, ví dụ hệ thống RAG phục vụ nghiên cứu hoặc kiểm chứng dữ liệu.
Nguyên tắc: Thay vì ghi đè vector cũ, bạn tạo embedding mới với phiên bản mới (version) và đánh dấu vector cũ là inactive.
Ví dụ:
collection.add(
documents=["Tài liệu phiên bản 4"],
ids=["doc_123_v4"],
metadatas=[{"active": True, "version": 4}]
)
collection.update(ids=["doc_123_v3"], metadatas={"active": False})
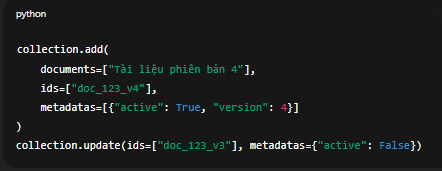
Ưu điểm:
Nhược điểm: Tốn dung lượng lưu trữ hơn.
Phù hợp: Các hệ thống AI cần truy vết hoặc phân tích phiên bản dữ liệu.
Bạn không thể chỉ dựa vào trực giác. Hệ thống cần trigger hoặc cơ chế tự động phát hiện khi dữ liệu thay đổi. Dưới đây là ba kỹ thuật phổ biến:
Lưu last_updated_at trong database, hoặc tạo hash (content) để xác định xem dữ liệu đã đổi chưa.
import hashlib
def content_hash(text):
return hashlib.md5(text.encode('utf-8')).hexdigest()
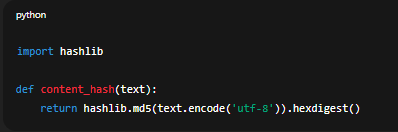
Nếu hash khác so với hash lưu trước đó → cập nhật embedding.
Khi người dùng chỉnh sửa tài liệu, hệ thống gửi event tới service embedding:
{
"event": "document_updated",
"id": "doc_001",
"source": "blog"
}
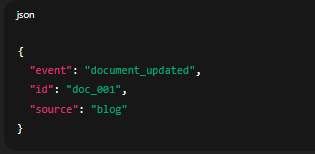
Worker nhận event và xử lý cập nhật embedding tương ứng.
Với hệ thống lớn, có thể chạy cron job mỗi 24h để rà soát những bản ghi có thay đổi, sau đó cập nhật embedding theo lô (batch).
Một Embedding Update Pipeline điển hình gồm 5 bước:
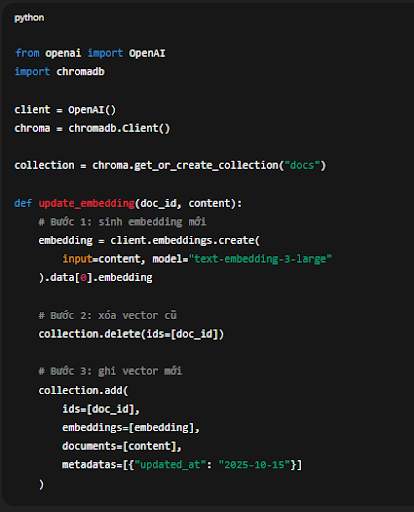
Ví dụ pipeline với Python + ChromaDB:
from openai import OpenAI
import chromadbclient = OpenAI()
chroma = chromadb.Client()collection = chroma.get_or_create_collection("docs")
def update_embedding(doc_id, content):
# Bước 1: sinh embedding mới
embedding = client.embeddings.create(
input=content, model="text-embedding-3-large"
).data[0].embedding# Bước 2: xóa vector cũ
collection.delete(ids=[doc_id])# Bước 3: ghi vector mới
collection.add(
ids=[doc_id],
embeddings=[embedding],
documents=[content],
metadatas=[{"updated_at": "2025-10-15"}]
)
Khi bạn phải cập nhật hàng trăm nghìn vector, cần chú ý tới hiệu suất:
Điều này giúp giảm tải GPU/CPU và giữ hệ thống ổn định.
Việc xóa dữ liệu cũng cần xử lý khéo để không ảnh hưởng đến kết quả tìm kiếm:
Việc cập nhật embedding khi dữ liệu thay đổi là bước không thể thiếu để duy trì tính chính xác, ổn định và tin cậy của các hệ thống AI dựa trên tìm kiếm ngữ nghĩa. Một chiến lược thông minh nên kết hợp:
Cập nhật embedding không chỉ là công việc bảo trì mà là trụ cột bảo đảm tính toàn vẹn ngữ nghĩa của toàn bộ hệ thống AI và RAG mà bạn đang vận hành.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
