 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong các hệ thống RAG, việc chia nhỏ tài liệu (chunking) là bước tiền xử lý phổ biến. Tuy nhiên, nếu bạn chọn chunk_size quá nhỏ hoặc chunk_overlap quá lớn/nhỏ, bạn rất dễ mất ngữ cảnh hoặc tốn tài nguyên và làm giảm độ chính xác. Trong bài viết này, Bizfly sẽ hướng dẫn bạn cách tối ưu kích thước chunk trong RAG chính xác từ thiết lập kịch bản thử nghiệm, đánh giá kết quả, đến các mẹo tối ưu để bạn có thể áp dụng ngay cho hệ thống của mình.
Trong các hệ thống Retrieval-Augmented Generation (RAG) hay các pipeline xử lý văn bản như Semantic Search, Question Answering, hoặc AI Agent có trí nhớ dài hạn, việc chia tài liệu thành các “chunk” nhỏ là bước không thể thiếu.
Chunk là những đoạn văn bản được tách ra từ tài liệu gốc thường tính theo đơn vị token từ hoặc câu nhằm phục vụ cho việc lưu trữ vector embedding và truy xuất nhanh hơn.
Điều đó có nghĩa là chunk_size và chunk_overlap ảnh hưởng trực tiếp đến:
Do vậy, để tối ưu mô hình RAG hay bất kỳ hệ thống AI nào có thành phần vector search, bạn cần thực hiện thử nghiệm có kiểm soát để tìm ra kích thước chunk lý tưởng cho dữ liệu của mình.
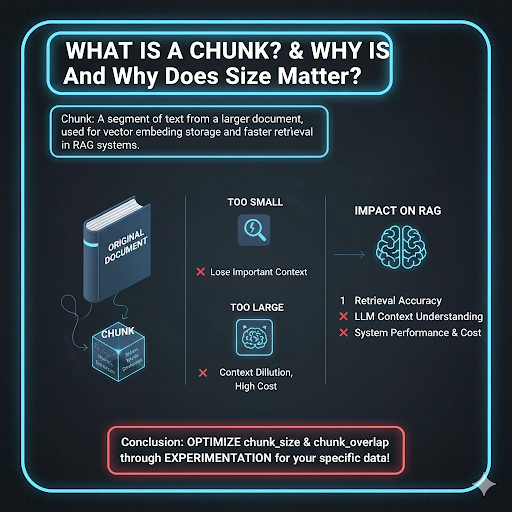
Đây là số lượng token (hoặc ký tự, từ) trong một đoạn nhỏ được tạo ra từ tài liệu gốc.
Chunk_overlap cho phép phần cuối của một chunk “giao nhau” với phần đầu của chunk tiếp theo, tránh việc cắt rời ý quan trọng.
Ví dụ:
chunk_size = 800, overlap = 100
→ Chunk 1: token 0–800
→ Chunk 2: token 700–1.500
Nếu overlap quá nhỏ (0–10 token), mô hình có thể “quên” ngữ cảnh giữa các đoạn; nhưng nếu overlap quá lớn (200–400 token), tài nguyên xử lý và lưu trữ tăng không cần thiết.

Thay vì chọn giá trị ngẫu nhiên, bạn nên thiết kế thí nghiệm thực nghiệm (empirical experiment) có quy trình rõ ràng:
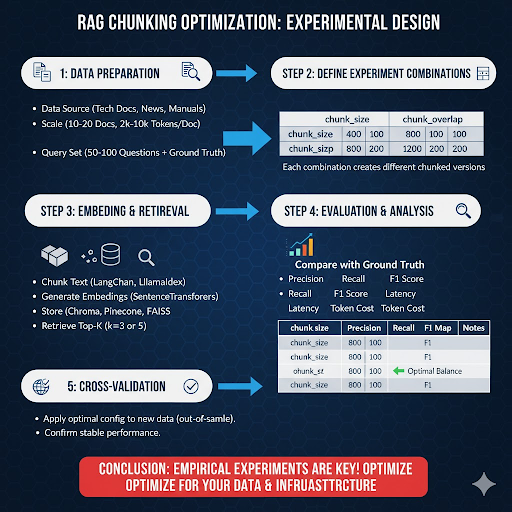
Nguồn dữ liệu: Chọn tập văn bản tương ứng với loại nội dung bạn sẽ dùng trong RAG (VD: tài liệu kỹ thuật, tin tức, hướng dẫn sản phẩm…).
Chọn danh sách các giá trị để thử:
| chunk_size | chunk_overlap |
| 200 | 50 |
| 400 | 100 |
| 800 | 100 |
| 800 | 200 |
| 1200 | 200 |
Mỗi tổ hợp sẽ được áp dụng lên toàn bộ tập dữ liệu để tạo ra các phiên bản chunk khBước 3: Tạo embedding và thực hiện truy xuất
Sử dụng công cụ LangChain, LlamaIndex, hoặc Haystack để:
Kết quả được tổng hợp vào bảng so sánh như sau:
| chunk_size | overlap | Precision | Recall | F1 | Map | Ghi chú |
| 200 | 50 | 0.72 | 0.60 | 0.65 | 0.66 | Thiếu ngữ cảnh |
| 400 | 100 | 0.81 | 0.77 | 0.79 | 0.80 | Cân bằng |
| 800 | 100 | 0.86 | 0.82 | 0.84 | 0.85 | Rất ổn định |
| 800 | 200 | 0.87 | 0.83 | 0.85 | 0.86 | Chi phí cao hơn |
| 1200 | 200 | 0.82 | 0.89 | 0.85 | 0.84 | Dư thừa dữ liệu |
Từ kết quả này, có thể thấy: cấu hình chunk_size = 800, overlap = 100–200 đạt hiệu suất tốt nhất giữa độ chính xác và chi phí.
Sau khi xác định cấu hình tối ưu, hãy áp dụng nó lên bộ dữ liệu mới (out-of-sample) để kiểm chứng xem hiệu suất có còn ổn định không. Nếu độ chính xác giảm nhiều, có thể bạn đã “overfit” cho tập cũ → cần tinh chỉnh lại.
Thay vì cắt theo số token, dùng mô hình embedding hoặc sentence transformer để nhóm các câu có ý nghĩa tương tự nhau thành một chunk.
Ví dụ: chia theo tiêu đề (heading), mục nhỏ, danh sách hoặc đoạn văn có dấu chấm câu rõ ràng. Cách này hữu ích với tài liệu kỹ thuật hoặc hướng dẫn sản phẩm, nơi cấu trúc logic rất quan trọng.
Giữ chunk_size cố định nhưng cho phép cửa sổ di chuyển có độ chồng nhất định.
Ví dụ:
chunk_size = 800
step = 600 (tức overlap = 200) → Mỗi lần cửa sổ di chuyển 600 token, tạo thành chuỗi chunk có vùng giao nhau 200 token.
Kỹ thuật này giúp duy trì ngữ cảnh mượt hơn giữa các đoạn.
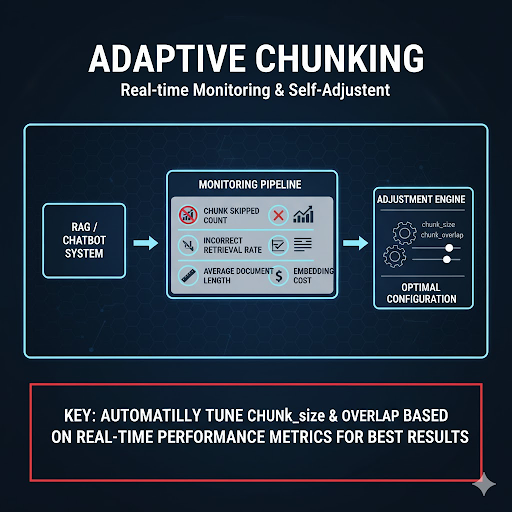
Nếu bạn đang triển khai RAG hoặc Chatbot AI trong môi trường thực tế, có thể xây một pipeline tự động theo dõi:
Hệ thống có thể tự điều chỉnh chunk_size & overlap dựa trên thống kê đó để đạt hiệu năng tốt nhất.
Ví dụ:
Chunk theo ngữ nghĩa trước → cắt thêm theo token để đảm bảo giới hạn kỹ thuật của embedding model.
Hoặc
Chunk theo heading → áp dụng overlap động (nhiều hơn ở phần mô tả, ít hơn ở phần liệt kê).
def chunk_text(text, chunk_size, overlap):
chunks = []
start = 0
while start end = min(start + chunk_size, len(text))
chunks.append(text[start:end])
start += chunk_size - overlap
return chunksconfigs = [(200,50),(400,100),(800,100),(800,200),(1200,200)]
results = []for cs, ov in configs:
all_chunks = [chunk_text(doc, cs, ov) for doc in documents]
vector_db = build_vector_db(all_chunks)
metrics = evaluate_retrieval(vector_db, queries, ground_truth)
results.append({"chunk_size": cs, "overlap": ov, **metrics})best = max(results, key=lambda r: r['F1'])
print("Cấu hình tốt nhất:", best)

Dựa trên bảng kết quả, bạn có thể:
Ví dụ:
- Nếu accuracy tăng 2% nhưng chi phí tăng 50%, cấu hình đó không đáng chọn.
- Ngược lại, nếu accuracy tăng 10% với chi phí tăng nhẹ 10–15%, có thể chấp nhận.
| Sai lầm | Hệ quả | Giải pháp |
| Chọn chunk_size theo cảm tính | Mất ngữ cảnh hoặc dư thừa dữ liệu | Luôn có bước test có kiểm soát |
| Overlap quá lớn | Tăng chi phí embedding & trùng dữ liệu | Giữ overlap |
| Chia chunk giữa câu hoặc bảng biểu | Mất logic nội dung | Chia theo dấu câu hoặc markup |
| Không cập nhật chunk_size khi thay mô hình embedding | Mất độ tương thích |
Điều chỉnh theo token limit của model mới |
| Loại nội dung | chunk_size | overlap | Ghi chú |
| FAQ, chatbot hỗ trợ khách hàng | 300–500 | 50–100 | Ngữ cảnh ngắn, nên overlap nhỏ |
| Tài liệu kỹ thuật, hướng dẫn sản phẩm | 600-900 | 100–200 | Ngữ cảnh dài, giữ continuity |
| Tài liệu học thuật hoặc pháp lý | 1000-1200 | 150–250 | Duy trì logic chặt chẽ |
| Dữ liệu hội thoại (chatlog, transcript) | 200-400 | 50–100 | Chia theo lượt nói |
Việc tối ưu kích thước chunk và mức overlap là một trong những yếu tố quyết định đến hiệu suất và độ chính xác của hệ thống RAG hay bất kỳ pipeline xử lý ngôn ngữ nào có bước truy xuất dữ liệu. Qua quá trình thực nghiệm từ thiết lập bộ dữ liệu, chọn cấu hình, đánh giá hiệu năng đến phân tích chi phí, bạn có thể xác định được cấu hình chunk_size và overlap lý tưởng nhất cho từng loại tài liệu.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
