 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong quá trình xử lý dữ liệu văn bản cho AI và các ứng dụng NLP, việc chia nhỏ dữ liệu (chunking) là bước quan trọng để đảm bảo mô hình hiểu đúng ngữ cảnh. Semantic Chunking – cắt dữ liệu dựa trên ý nghĩa nội dung giúp tách văn bản theo câu hoặc đoạn trọn vẹn, tránh tình trạng cắt giữa chừng làm mất mạch ý.
Semantic Chunking (cắt dữ liệu dựa trên ý nghĩa nội dung) là phương pháp chia văn bản thành các khối (chunk) sao cho mỗi khối vẫn giữ được ngữ cảnh trọn vẹn, thường là theo câu hoặc đoạn văn. Khác với cách cắt theo số token hoặc ký tự – vốn có thể khiến văn bản bị đứt đoạn giữa chừng – Semantic Chunking ưu tiên giữ nguyên thông điệp, đảm bảo AI có thể đọc hiểu và xử lý thông tin đầy đủ.
Ví dụ:
Việc tuân thủ đúng quy trình trên giúp đảm bảo mỗi chunk vừa có độ dài phù hợp, vừa giữ được ngữ cảnh đầy đủ. Đây chính là nền tảng quan trọng để các bước ứng dụng tiếp theo như RAG, Semantic Search hay Chatbot AI hoạt động hiệu quả và chính xác hơn.
Mục tiêu: loại bỏ các ký tự không cần thiết, làm sạch dữ liệu đầu vào.
Cách thực hiện:
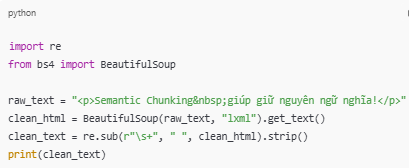
import re
from bs4 import BeautifulSoupraw_text = "
Semantic Chunking giúp giữ nguyên ngữ nghĩa!
"
clean_html = BeautifulSoup(raw_text, "lxml").get_text()
clean_text = re.sub(r"\s+", " ", clean_html).strip()
print(clean_text)
Mục tiêu: chia văn bản thành câu hoặc đoạn để giữ ý nghĩa liền mạch.
Cách thực hiện:
from underthesea import sent_tokenize
text = "Semantic Chunking giúp giữ nguyên ngữ nghĩa. Nó rất hữu ích cho AI."
sentences = sent_tokenize(text)print(sentences)

Mục tiêu: đảm bảo chunk không quá ngắn, không quá dài.
Quy tắc:
def merge_sentences(sentences, max_tokens=300):
chunks, current = [], []
count = 0
for s in sentences:
tokens = len(s.split())
if count + tokens current.append(s)
count += tokens
else:
chunks.append(" ".join(current))
current = [s]
count = tokens
if current:
chunks.append(" ".join(current))
return chunks

Mục tiêu: giúp dễ dàng quản lý, tìm kiếm, và map dữ liệu về đúng vị trí ban đầu.
Cách thực hiện:
chunks = ["Semantic Chunking giúp giữ nguyên ngữ nghĩa.",
"Nó rất hữu ích cho AI."]
metadata = [
{"doc_id": 1, "section": "intro", "chunk_id": i, "content": c}
for i, c in enumerate(chunks, 1)
]
print(metadata)

Mục tiêu: lưu dữ liệu đã chunked để phục vụ embedding hoặc search.
Cách thực hiện: Xuất ra CSV (dễ xem thủ công) hoặc JSON (dễ tích hợp API).
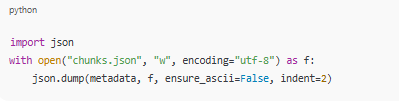
import json
with open("chunks.json", "w", encoding="utf-8") as f:
json.dump(metadata, f, ensure_ascii=False, indent=2)
Kết quả: mỗi chunk là một record riêng, có metadata đi kèm → dễ dàng load vào vector DB như Pinecone, Weaviate, Milvus hoặc FAISS.
Tóm lại: Quy trình Semantic Chunking gồm làm sạch dữ liệu → tách câu/đoạn → gom chunk theo token → gắn metadata → export dữ liệu. Nếu dev áp dụng đúng, thì pipeline sẽ cho ra dữ liệu vừa sạch, vừa giữ ngữ nghĩa, sẵn sàng cho embedding & RAG.
Ví dụ code Python với NLTK:
import nltk
nltk.download('punkt')
text = """Semantic Chunking giúp giữ nguyên ngữ nghĩa.
Nó rất hữu ích cho AI khi triển khai RAG hoặc chatbot."""
sentences = nltk.sent_tokenize(text)
chunks = [s for s in sentences]
for i, c in enumerate(chunks, 1):
print(f"Chunk {i}: {c}")

Kết quả

Semantic Chunking không chỉ đơn thuần là một kỹ thuật cắt văn bản, mà còn là cách giúp AI và các hệ thống NLP hiểu con người tốt hơn. Thay vì để dữ liệu bị chia nhỏ một cách máy móc, phương pháp này giữ trọn ý nghĩa trong từng chunk, từ đó mang lại độ chính xác và trải nghiệm vượt trội trong các ứng dụng AI hiện đại.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
