Khi xây dựng một Agent AI có khả năng giao tiếp tự nhiên, việc quản lý trí nhớ hay trạng thái hội thoại (conversational state) là một trong những bài toán xương sống quyết định đến độ thông minh và hiệu quả của Agent. Bài viết này sẽ phân tích cách chúng ta có thể lưu trữ và truy xuất trạng thái hội thoại một cách hiệu quả.
Thành phần hệ thống cần có khi lưu trữ và truy xuất trạng thái
Để xây dựng một cơ chế quản lý trạng thái hội thoại hoàn chỉnh, hệ thống của chúng ta không chỉ có mỗi con LLM. Nó là sự kết hợp của nhiều thành phần, mỗi thằng giữ một vai trò riêng:
- User Interface (UI): Giao diện để người dùng tương tác, có thể là web app, mobile app, hoặc một terminal đơn giản.
- API Gateway: Đóng vai trò là cổng chính, tiếp nhận request từ UI, xác thực và điều hướng đến các service cần thiết. Nó đảm bảo các request được xử lý một cách an toàn và có tổ chức.
- Orchestrator/Agent Core: Đây là bộ não trung tâm, nơi điều phối toàn bộ luồng xử lý. Nó sẽ nhận yêu cầu từ API Gateway, quyết định xem cần gọi đến service nào, lấy thông tin gì từ database, và khi nào thì cần hỏi ý kiến của LLM. Framework như LangChain hay LlamaIndex thường đóng vai trò này.
- Large Language Model (LLM): Trái tim của Agent, chịu trách nhiệm sinh ra nội dung, hiểu ngữ cảnh và đưa ra phản hồi. Đây có thể là các model từ OpenAI (GPT-4), Google (Gemini), hoặc các model open-source khác. Bản thân LLM vốn là stateless, nó không tự nhớ các cuộc hội thoại trước đó nếu không được cung cấp lại context.
- Database (DB): Nơi lưu trữ trạng thái hội thoại. Tùy vào kiến trúc và yêu cầu, chúng ta có thể dùng nhiều loại DB khác nhau:
- Cache (e.g., Redis): Dùng để lưu các session hội thoại ngắn hạn, truy xuất cực nhanh. Rất hữu ích để giữ context trong một phiên làm việc.
- NoSQL Database (e.g., MongoDB, DynamoDB): Linh hoạt trong việc lưu trữ dữ liệu dưới dạng JSON hoặc document, phù hợp để lưu toàn bộ lịch sử chat, thông tin user, và các metadata liên quan.
- Vector Database (e.g., Pinecone, Chroma, Milvus): Thành phần cực kỳ quan trọng trong các hệ thống RAG (Retrieval-Augmented Generation). Nó vector hóa các đoạn hội thoại hoặc tài liệu và lưu trữ dưới dạng vector embedding, giúp tìm kiếm thông tin liên quan theo ngữ nghĩa (semantic search) thay vì chỉ bằng keyword.
- Data/Knowledge Base: Nguồn tri thức riêng của Agent. Đây có thể là tài liệu sản phẩm, database của công ty, hay bất kỳ nguồn dữ liệu nào mà Agent cần truy cập để trả lời các câu hỏi chuyên sâu.
Luồng hoạt động lưu trữ và truy xuất chi tiết của Agent AI
Để hiểu rõ hơn, hãy debug từng bước hoạt động của hệ thống khi user gửi một tin nhắn. Luồng hoạt động (Sequence Flow) như sau:
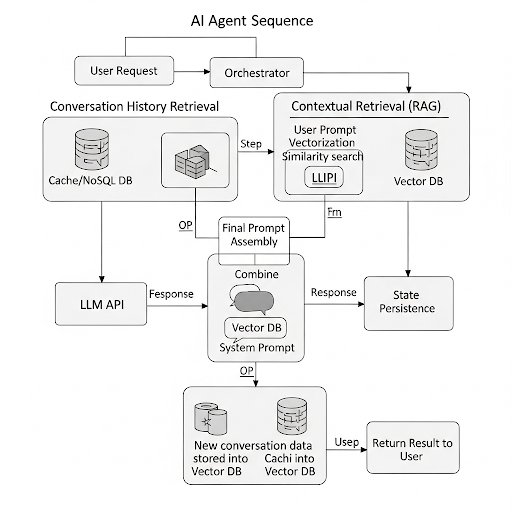
1. User Request: Người dùng nhập một câu hỏi (prompt) qua UI. Request này được đóng gói (thường là JSON) chứa user_id, session_id, và message_content rồi gửi đến API Gateway.
2. Orchestrator tiếp nhận: API Gateway chuyển tiếp request đến Orchestrator.
3. Truy xuất lịch sử hội thoại (Conversation History Retrieval):
- Orchestrator sử dụng session_id để query vào Cache (Redis) hoặc NoSQL DB (MongoDB) để lấy những tin nhắn gần nhất trong cuộc hội thoại hiện tại. Đây là bước cơ bản nhất để Agent "nhớ" những gì vừa nói.
- Ví dụ: Lấy 10 tin nhắn cuối cùng để làm context ngắn hạn.
4. Truy xuất ngữ cảnh liên quan (Contextual Retrieval - RAG):
- Orchestrator không chỉ lấy lịch sử chat, mà còn phân tích prompt của người dùng để tìm kiếm thông tin liên quan trong Vector DB.
- Prompt của user sẽ được một Embedding Model (ví dụ: text-embedding-ada-002 của OpenAI) chuyển thành một vector.
- Orchestrator dùng vector này để thực hiện một truy vấn similarity search trong Vector DB. Kết quả trả về là những đoạn văn bản (chunks) có ngữ nghĩa gần nhất với câu hỏi của người dùng.
5. Tổng hợp Prompt cuối cùng (Final Prompt Assembly):
Orchestrator sẽ đưa tất cả thông tin đã thu thập được vào một cái prompt hoàn chỉnh để gửi cho LLM. Cấu trúc của prompt này rất quan trọng, thường bao gồm:
- System Prompt: Chỉ thị vai trò, phong cách cho LLM (e.g., "Bạn là một trợ lý kỹ thuật chuyên sâu...").
- Retrieved Context: Các thông tin lấy từ Vector DB (e.g., "Dựa vào thông tin sau: [context-from-vector-db]...").
- Conversation History: Lịch sử hội thoại ngắn hạn (e.g., "Đây là những gì chúng ta vừa nói: [chat-history]...").
- User's Current Question: Câu hỏi hiện tại của người dùng.
6. Gọi đến LLM: Orchestrator gửi Final Prompt này đến API của LLM.
7. LLM xử lý và phản hồi (Response Generation): LLM nhận prompt, phân tích toàn bộ ngữ cảnh được cung cấp và sinh ra câu trả lời.
8. Lưu trữ trạng thái mới (State Persistence):
- Orchestrator nhận phản hồi từ LLM.
- Cặp "câu hỏi của user" và "câu trả lời của Agent" sẽ được lưu lại vào DB (cả NoSQL và Cache) với session_id tương ứng.
- Đồng thời, cặp hội thoại này cũng có thể được đưa vào một background process để vector hóa và lưu vào Vector DB, làm giàu thêm kiến thức cho các lần truy vấn sau.
9. Trả kết quả về cho User: Orchestrator gửi câu trả lời cuối cùng về lại cho UI thông qua API Gateway.
Thiết kế schema lưu trữ
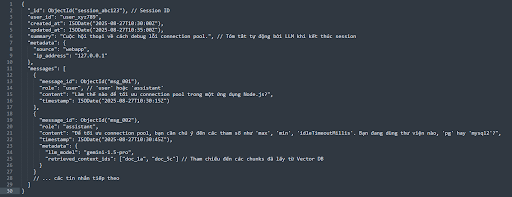
Việc thiết kế schema quyết định khả năng mở rộng và hiệu quả truy vấn. Dưới đây là một ví dụ về schema sử dụng MongoDB:
Collection: conversations
{
"_id": ObjectId("session_abc123"), // Session ID
"user_id": "user_xyz789",
"created_at": ISODate("2025-08-27T10:30:00Z"),
"updated_at": ISODate("2025-08-27T10:35:00Z"),
"summary": "Cuộc hội thoại về cách debug lỗi connection pool.", // Tóm tắt tự động bởi LLM khi kết thúc session
"metadata": {
"source": "webapp",
"ip_address": "127.0.0.1"
},
"messages": [
{
"message_id": ObjectId("msg_001"),
"role": "user", // 'user' hoặc 'assistant'
"content": "Làm thế nào để tối ưu connection pool trong một ứng dụng Node.js?",
"timestamp": ISODate("2025-08-27T10:30:15Z")
},
{
"message_id": ObjectId("msg_002"),
"role": "assistant",
"content": "Để tối ưu connection pool, bạn cần chú ý đến các tham số như 'max', 'min', 'idleTimeoutMillis'. Bạn đang dùng thư viện nào, 'pg' hay 'mysql2'?",
"timestamp": ISODate("2025-08-27T10:30:45Z"),
"metadata": {
"llm_model": "gemini-1.5-pro",
"retrieved_context_ids": ["doc_1a", "doc_5c"] // Tham chiếu đến các chunks đã lấy từ Vector DB
}
}
// ... các tin nhắn tiếp theo
]
}
Tại sao thiết kế này hiệu quả?
- Lấy session làm gốc (_id): Dễ dàng query toàn bộ một cuộc hội thoại.
- Mảng messages: Giữ được thứ tự và cấu trúc của cuộc hội thoại một cách tự nhiên.
- metadata: Cung cấp thông tin phụ trợ cho việc debug, phân tích và thậm chí là security. retrieved_context_ids giúp chúng ta trace lại được Agent đã dựa vào nguồn tri thức nào để trả lời.
- summary: Giúp tóm tắt nội dung để con người hoặc một agent khác có thể nhanh chóng nắm bắt ngữ cảnh mà không cần đọc lại toàn bộ.
Những vấn đề cần mà dân công nghệ cần lưu ý khi thực hiện
Lý thuyết là vậy, nhưng khi bắt tay vào code, anh em sẽ phải đối mặt với vài vấn đề khá khoai:
- Context Window Limitation: LLM có giới hạn về lượng token nó có thể xử lý trong một lần gọi (e.g., 4k, 8k, 128k tokens). Nhồi quá nhiều lịch sử chat và context từ RAG sẽ làm tràn bộ nhớ này. Cần có chiến lược tối ưu thông minh, ví dụ: chỉ lấy N tin nhắn cuối, hoặc dùng một LLM khác để tóm tắt các đoạn hội thoại cũ trước khi đưa vào prompt.
- Latency (Độ trễ): Luồng hoạt động ở trên có rất nhiều bước I/O (query DB, gọi API LLM). Mỗi bước đều cộng thêm độ trễ. Việc tối ưu query DB, sử dụng cache, và chọn model LLM có tốc độ phù hợp là cực kỳ quan trọng để trải nghiệm người dùng không bị khựng lại.
- Chi phí (Cost): Mỗi lần gọi API LLM đều tốn tiền. Một prompt dài với nhiều context sẽ tốn nhiều token hơn. Cần cân bằng giữa chất lượng câu trả lời (cung cấp nhiều context) và chi phí (giữ prompt gọn gàng).
- Tính chính xác của RAG: Vector search không phải lúc nào cũng trả về context chuẩn 100%. Kết quả rác từ RAG sẽ dẫn đến câu trả lời ảo giác (hallucination) từ LLM. Cần tinh chỉnh (fine-tuning) embedding model, thử các chiến lược chunking dữ liệu khác nhau, hoặc re-ranking kết quả tìm kiếm.
- Quản lý Session: Xác định khi nào một session bắt đầu và kết thúc một cách hợp lý. Session quá dài sẽ làm loãng context, session quá ngắn lại khiến Agent hay quên. Có thể implement cơ chế timeout hoặc cho phép người dùng chủ động reset session.
- Bảo mật và quyền riêng tư (Security & Privacy): Lịch sử hội thoại có thể chứa thông tin nhạy cảm. Cần mã hóa dữ liệu (at-rest và in-transit) và có cơ chế phân quyền rõ ràng để đảm bảo chỉ những người có quyền mới được truy cập.
Kết luận
Việc xây dựng cơ chế lưu trữ và truy xuất trạng thái hội thoại cho Agent AI là một bài toán đa tầng, đòi hỏi sự kết hợp nhuần nhuyễn giữa kiến trúc hệ thống, lựa chọn công nghệ và các thuật toán xử lý. Hiểu rõ cách các thành phần như Orchestrator, LLM và các loại Database tương tác với nhau, cùng với việc lường trước các thách thức về latency, cost và context window, chính là chìa khóa để xây dựng nên những Agent AI thực sự thông minh và hữu ích.
 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
 Đỗ Minh Đức
Đỗ Minh Đức



 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
