 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Khi xây dựng một AI Agent có khả năng "nhớ" và phản hồi thông minh, vector database là nền tảng không thể thiếu. Nó giúp mô hình tìm kiếm và truy xuất thông tin tương đồng từ hàng ngàn tài liệu chỉ trong vài mili-giây. Trong bài viết này, Bizfly sẽ cùng tìm hiểu cách cài đặt quản lý Vector Database cho AI Agent qua ChromaDB hoặc FAISS phù hợp cho các dự án nhỏ hoặc cá nhân.
Vector database (hay còn gọi là cơ sở dữ liệu vector) là nơi lưu trữ embedding, dạng biểu diễn dữ liệu (văn bản, hình ảnh, âm thanh...) dưới dạng vector số. Khi AI Agent nhận câu hỏi từ người dùng, nó sẽ:
Điều này giúp mô hình trả lời chính xác và có ngữ cảnh, thay vì chỉ dựa trên nội dung ngắn hạn trong bộ nhớ tạm.
Trên thị trường có nhiều lựa chọn Vector DB như Pinecone, Weaviate, Milvus, Qdrant,… nhưng với dự án nhỏ hoặc demo, ChromaDB và FAISS là hai công cụ phổ biến nhất vì dễ cài đặt và không cần server riêng.
| Tiêu chí | ChromaDB | FAISS |
| Ngôn ngữ hỗ trợ | Python, JS | Python, C++ |
| Triển khai | Cài trực tiếp, lưu local | In-memory hoặc index file |
| Tốc độ | Nhanh với ≤100k vector | Cực nhanh, tối ưu GPU |
| Tính năng | Có API lưu trữ, metadata, filter | Tối ưu cho tìm kiếm vector thuần |
| Use case phù hợp | AI Agent nhỏ, chatbot nội bộ | Hệ thống tìm kiếm lớn, nhiều tài liệu |
Kết luận:
pip install chromadb sentence-transformers

Ở đây ta dùng sentence-transformers để tạo embedding và chromadb để lưu trữ vector.
from sentence_transformers import SentenceTransformer
import chromadb# Khởi tạo model & client DB
model = SentenceTransformer('all-MiniLM-L6-v2')
client = chromadb.Client()
collection = client.create_collection(name="docs")# Danh sách tài liệu
texts = [
"Bizfly là hệ sinh thái Martech & Salestech thuộc VCCorp.",
"AI Agent cần Vector DB để ghi nhớ ngữ cảnh cuộc trò chuyện.",
"ChromaDB phù hợp cho dự án AI nhỏ và dễ triển khai."
]# Tạo embedding
embeddings = model.encode(texts)# Thêm vào collection
collection.add(
documents=texts,
embeddings=embeddings,
ids=["1", "2", "3"]
)
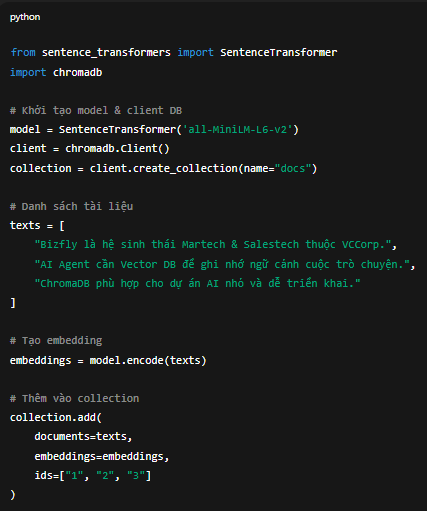
Khi chạy xong, bạn đã có một database nội bộ lưu trữ 3 vector tương ứng 3 đoạn văn.
query = "Cách AI lưu kiến thức hội thoại?"
query_emb = model.encode([query])results = collection.query(
query_embeddings=query_emb,
n_results=2
)print(results['documents'])
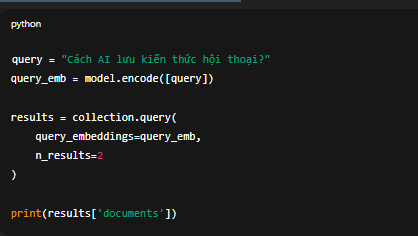
ChromaDB trả về 2 đoạn văn có ý nghĩa gần nhất với câu hỏi của bạn, dựa trên độ tương đồng cosine.
Nếu bạn không muốn mất dữ liệu khi khởi động lại chương trình:
client = chromadb.PersistentClient(path="data/chroma_db")

Thư mục data/chroma_db sẽ chứa toàn bộ dữ liệu và có thể backup dễ dàng.
pip install faiss-cpu sentence-transformers
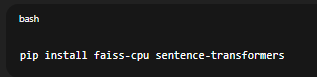
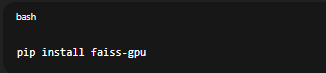
Nếu bạn có GPU, dùng:
pip install faiss-gpu
import faiss
import numpy as np
from sentence_transformers import SentenceTransformermodel = SentenceTransformer('all-MiniLM-L6-v2')
texts = [
"FAISS được Meta phát triển để tối ưu tìm kiếm vector.",
"FAISS hoạt động tốt với hàng triệu bản ghi vector.",
"FAISS có thể chạy trên CPU hoặc GPU."
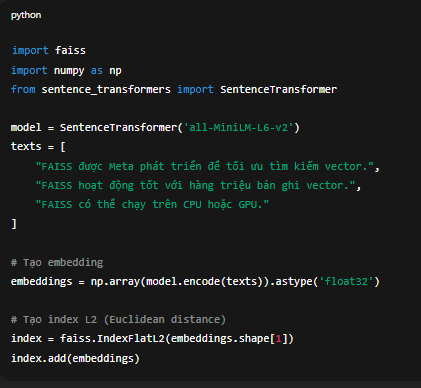
]# Tạo embedding
embeddings = np.array(model.encode(texts)).astype('float32')# Tạo index L2 (Euclidean distance)
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)
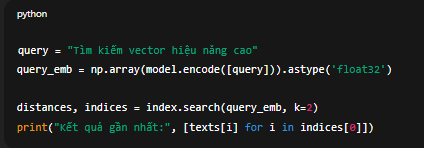
query = "Tìm kiếm vector hiệu năng cao"
query_emb = np.array(model.encode([query])).astype('float32')distances, indices = index.search(query_emb, k=2)
print("Kết quả gần nhất:", [texts[i] for i in indices[0]])
Bạn có thể kết hợp FAISS với metadata hoặc SQLite để lưu thêm thông tin (như tiêu đề, link nguồn,...). Ví dụ: lưu FAISS vector, nhưng metadata lại lưu trong SQLite hoặc JSON file.
Một AI Agent hoàn chỉnh thường có pipeline như sau:
Input người dùng
↓
Tạo embedding cho câu hỏi
↓
Tìm kiếm ngữ cảnh liên quan trong Vector DB (ChromaDB/FAISS)
↓
Kết hợp ngữ cảnh + câu hỏi → gửi vào LLM (GPT/BizChatAI)
↓
Sinh câu trả lời có ngữ cảnh
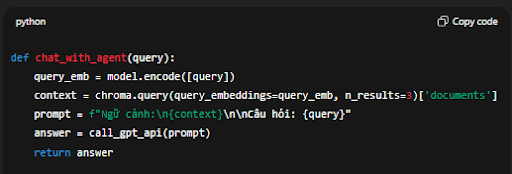
Ví dụ bằng pseudo-code:
def chat_with_agent(query):
query_emb = model.encode([query])
context = chroma.query(query_embeddings=query_emb, n_results=3)['documents']
prompt = f"Ngữ cảnh:\n{context}\n\nCâu hỏi: {query}"
answer = call_gpt_api(prompt)
return answer
AI Agent giờ đây có khả năng “truy xuất kiến thức riêng”, thay vì chỉ dựa vào thông tin huấn luyện sẵn.
Lúc đó, bạn có thể dùng FAISS GPU hoặc dịch vụ Pinecone/Milvus để mở rộng quy mô.

Trong hệ sinh thái Bizfly, BizChatAI đang tích hợp pipeline tương tự RAG (Retrieval-Augmented Generation) nơi ChromaDB đóng vai trò là bộ nhớ ngữ nghĩa cho chatbot doanh nghiệp.
Ví dụ: Khi khách hàng hỏi: “Chính sách bảo hành của sản phẩm A là gì?”, BizChatAI sẽ truy xuất các đoạn liên quan từ vector database (embedding tài liệu sản phẩm) rồi tạo câu trả lời chính xác, tự nhiên.
Điều này giúp doanh nghiệp giảm chi phí vận hành CSKH, tăng tốc độ phản hồi và đảm bảo tính thống nhất trong thông tin.
Vector database là nền tảng giúp AI Agent “ghi nhớ” và “hiểu ngữ cảnh” thông minh hơn.
Nếu bạn đang muốn triển khai chatbot, trợ lý ảo hay hệ thống AI có khả năng truy xuất kiến thức tự động nên việc quản lý tốt Vector DB là bước khởi đầu quan trọng.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
