 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong các dự án AI hiện đại, dữ liệu là “nhiên liệu” quyết định hiệu suất mô hình. Tuy nhiên, khi dữ liệu quá lớn hoặc không đồng nhất, mô hình có thể khó học được các ngữ cảnh chính xác. Bài viết này sẽ hướng dẫn cách tích hợp chunking vào pipeline huấn luyện AI một cách tự động giúp tối ưu hóa luồng xử lý dữ liệu, nâng cao tốc độ huấn luyện và độ chính xác tổng thể của mô hình.
Chunking hiểu đơn giản là quá trình chia nhỏ dữ liệu lớn thành nhiều phần nhỏ hơn (chunk) để mô hình học máy có thể xử lý từng phần một. Mục tiêu là giữ nguyên ngữ cảnh quan trọng, nhưng giảm tải lượng thông tin mỗi lần mô hình đọc.
Ví dụ:
Bạn có một tài liệu hướng dẫn dài 100.000 ký tự. Nếu cho mô hình đọc toàn bộ, sẽ vượt quá giới hạn context window (ví dụ 8.000 hoặc 16.000 token). Bằng cách chunking, bạn tách văn bản thành các đoạn 500–800 token, mỗi đoạn có thể xử lý riêng biệt, sau đó tổng hợp kết quả.
Lợi ích rõ ràng của chunking gồm:
Chunking không chỉ dùng trong fine-tuning LLM mà còn cực kỳ hữu ích cho các bài toán như document retrieval, question answering, semantic search hoặc AI Agent có bộ nhớ dài.
Một pipeline huấn luyện AI thông thường sẽ trải qua các giai đoạn sau:
Thu thập dữ liệu → Làm sạch → Tiền xử lý → Chunking → Embedding → Lưu trữ → Huấn luyện mô hình
Bước chunking nằm giữa khâu tiền xử lý và tạo embedding, đóng vai trò như cầu nối giúp dữ liệu được “nén thông minh” trước khi đi sâu vào quá trình huấn luyện.
Luồng hoạt động tổng quát:
Nhờ chunking, toàn bộ hệ thống xử lý dữ liệu trở nên linh hoạt, có thể mở rộng dễ dàng sang các mô hình khác mà không cần chỉnh lại dữ liệu gốc.
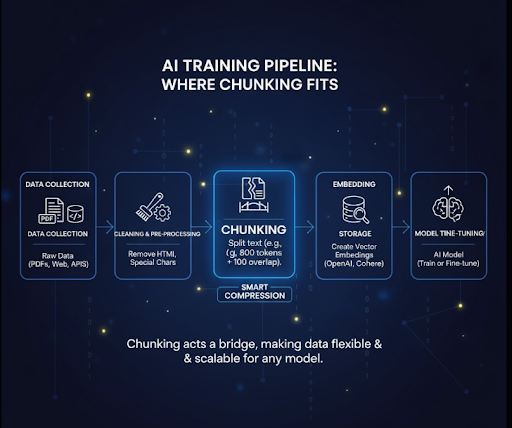
Dưới đây là ví dụ chi tiết bằng Python mô phỏng pipeline tự động hóa chunking với thư viện LangChain, công cụ phổ biến nhất hiện nay để thao tác văn bản trước khi tạo embedding.
from langchain.text_splitter import RecursiveCharacterTextSplitter
def clean_text(text):
text = text.replace("\n", " ").replace("\t", " ")
return " ".join(text.split())def chunk_documents(docs, chunk_size=500, chunk_overlap=100):
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
chunks = []
for doc in docs:
cleaned_doc = clean_text(doc)
chunks.extend(splitter.split_text(cleaned_doc))
return chunks# Pipeline mẫu
def ai_training_pipeline(raw_docs):
print("Bắt đầu pipeline huấn luyện AI...")
# 1. Tiền xử lý dữ liệu
print("Làm sạch dữ liệu...")
cleaned_data = [clean_text(doc) for doc in raw_docs]
# 2. Chunking dữ liệu
print("Thực hiện chunking...")
chunked_data = chunk_documents(cleaned_data)
# 3. Tạo embedding
print("Tạo embedding...")
embeddings = create_embeddings(chunked_data) # ví dụ: dùng OpenAI API
# 4. Huấn luyện mô hình
print("Huấn luyện mô hình...")
train_model(embeddings)
print("Pipeline hoàn tất!")

Điểm đáng chú ý:
Đây là hai tham số quan trọng nhất ảnh hưởng đến hiệu quả huấn luyện:
| Tham số | Ý nghĩa | Giá trị khuyến nghị |
| chunk_size | Độ dài tối đa mỗi đoạn văn bản (tính theo token hoặc ký tự). | 300–800 token với LLM tầm trung như GPT-3.5 hoặc Claude. |
| chunk_overlap | Phần chồng lặp giữa 2 chunk liền kề để giữ ngữ cảnh. | 10–20% kích thước chunk. |
| embedding_window | Độ dài tối đa của vector embedding. | Tùy theo model (512, 1024, 2048...). |
Sau khi thêm chunking vào pipeline, bạn có thể đánh giá hiệu quả dựa trên các chỉ số:
Nhiều nhóm kỹ sư đã ghi nhận rằng chunking giúp giảm 20–30% chi phí huấn luyện trong các pipeline lớn và tăng đáng kể độ chính xác khi truy hồi dữ liệu.
Khi triển khai ở môi trường thực tế, bạn có thể:
Chunking là bước trung gian nhỏ nhưng mang lại tác động lớn trong pipeline huấn luyện AI. Việc tích hợp chunking vào quy trình xử lý dữ liệu tự động giúp mô hình hiểu sâu hơn, giảm chi phí và dễ dàng mở rộng quy mô. Nếu bạn đang xây dựng pipeline cho dự án AI tại doanh nghiệp, hãy bắt đầu thử nghiệm với kỹ thuật này ngay hôm nay.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
