 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong thế giới của Large Language Models (LLM) để xây dựng một AI Agent thực sự hữu ích, có khả năng truy cập và xử lý thông tin private, thông tin real-time hoặc kiến thức chuyên ngành, chúng ta cần trang bị cho nó một bộ nhớ ngoài. Bài viết này sẽ đi sâu vào khía cạnh kỹ thuật, hướng dẫn anh em dev từng bước xây dựng một pipeline hoàn chỉnh để triển khai bộ nhớ cho AI Agent.
Mục tiêu của giai đoạn này là xây dựng một luồng (pipeline) tự động, đáng tin cậy để nạp dữ liệu từ nhiều nguồn khác nhau vào hệ thống. Đây là bước nền tảng, quyết định chất lượng đầu vào của toàn bộ hệ thống bộ nhớ của AI Agent.
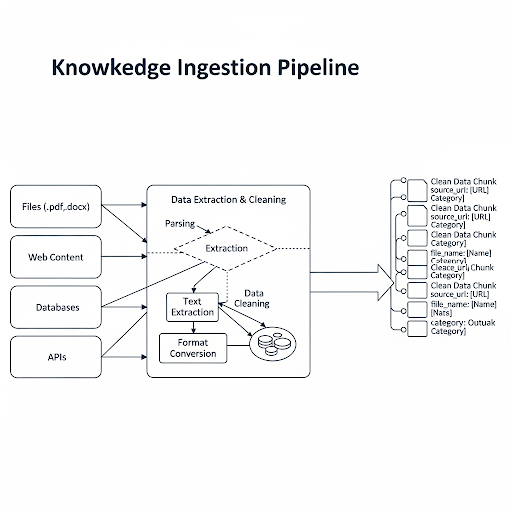
Đầu tiên, chúng ta cần xác định các nguồn dữ liệu. Dữ liệu có thể ở bất cứ đâu:
Để xử lý việc này, việc sử dụng các thư viện như LangChain với bộ DocumentLoaders là một lựa chọn cực kỳ hiệu quả. Mỗi loại loader được thiết kế để đọc và parse một định dạng dữ liệu cụ thể, trả về một đối tượng Document chuẩn hóa chứa content và metadata.
Dữ liệu thô thường chứa rất nhiều nhiễu: các thẻ HTML, ký tự đặc biệt, định dạng thừa... Giai đoạn này tập trung vào việc trích xuất phần text cốt lõi và làm sạch nó.
Trong quá trình load dữ liệu, đừng chỉ lấy content. Hãy trích xuất và gắn thêm metadata cho mỗi Document. Metadata có thể là:
Metadata cực kỳ hữu ích ở giai đoạn sau, cho phép chúng ta thực hiện các bộ lọc phức tạp khi truy vấn (ví dụ: "chỉ tìm kiếm trong các tài liệu thuộc category 'Kỹ thuật' được cập nhật trong tháng trước"). Một pipeline ingestion tốt cần phải robust, có khả năng logging và xử lý lỗi hiệu quả.
LLM có một giới hạn về số lượng token nó có thể xử lý trong một lần gọi, gọi là "context window". Chúng ta không thể đưa toàn bộ một tài liệu dài hàng trăm trang vào prompt. Do đó, ta phải chia nhỏ (chunking) tài liệu thành các đoạn nhỏ hơn, có ý nghĩa. Việc chọn chiến lược chunking ảnh hưởng trực tiếp đến chất lượng retrieval sau này.
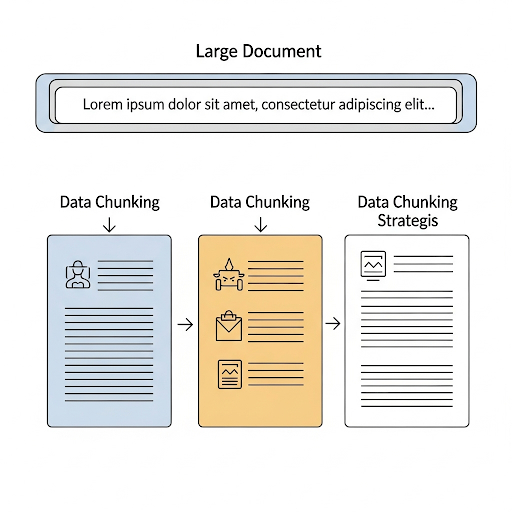
Đây là phương pháp đơn giản nhất: chia văn bản thành các chunk có kích thước cố định (ví dụ: 1000 ký tự) và có thể thêm một khoảng overlap (phần gối đầu giữa hai chunk liên tiếp để tránh mất ngữ cảnh).
Đây là phương pháp được sử dụng phổ biến và hiệu quả nhất hiện nay. Nó cố gắng chia văn bản dựa trên một danh sách các ký tự phân tách theo thứ tự ưu tiên. Ví dụ, nó sẽ thử chia theo \n\n (xuống dòng 2 lần - hết đoạn), nếu chunk vẫn quá dài, nó sẽ thử chia theo \n (xuống dòng), rồi đến dấu cách , rồi đến ký tự rỗng "".
Thay vì chia theo số lượng ký tự hoặc ký tự phân tách, phương pháp này chia văn bản dựa trên sự thay đổi về ngữ nghĩa. Nó tính toán khoảng cách (similarity score) giữa các câu liên tiếp bằng cách sử dụng embedding. Nếu khoảng cách giữa hai câu vượt một ngưỡng nhất định, nó sẽ tạo ra một điểm chia.
Lưu ý khi chunking:
Sau khi đã có các chunk dữ liệu, chúng ta cần một cách để máy tính hiểu được ngữ nghĩa của chúng. Đây là lúc Embedding và Vector Store vào cuộc.
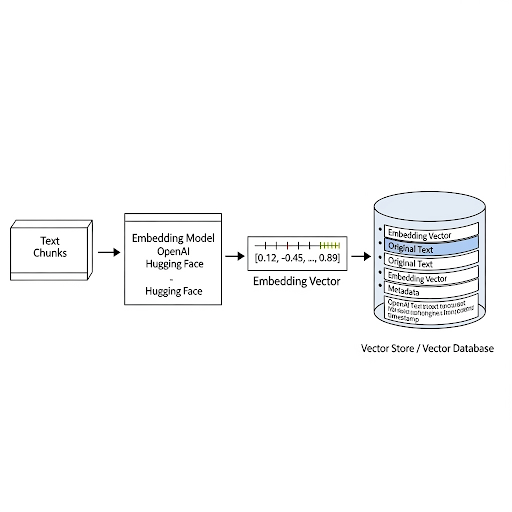
Embedding là quá trình chuyển đổi một đoạn text (chunk) thành một vector số thực (một mảng các con số, ví dụ: [0.12, -0.45, ..., 0.89]). Các mô hình embedding được train để những đoạn text có ngữ nghĩa tương tự nhau sẽ có vector ở gần nhau trong không gian vector.
Lựa chọn Embedding Model:
Proprietary (API): OpenAI text-embedding-3-small, text-embedding-3-large, các model của Cohere. Dễ dùng, hiệu năng cao.
Open-source: Các model từ Hugging Face như sentence-transformers/all-mpnet-base-v2 (tiếng Anh) hoặc bkai-foundation-models/vietnamese-bi-encoder (tiếng Việt). Cho phép self-host, toàn quyền kiểm soát.
Sau khi có các vector embedding, chúng ta cần một nơi để lưu trữ và truy vấn chúng một cách hiệu quả. Đây là nhiệm vụ của Vector Store. Chức năng chính của nó là thực hiện tìm kiếm tương đồng (similarity search) cực nhanh trên hàng triệu, thậm chí hàng tỷ vector.
Các lựa chọn Vector Store phổ biến:
Quy trình thực hiện: Lặp qua từng chunk dữ liệu -> Dùng embedding model để tạo vector -> Lưu trữ cặp (vector, original_text, metadata) vào Vector Store.
Đây là giai đoạn kết nối tất cả các thành phần lại với nhau để AI Agent có thể thực sự sử dụng bộ nhớ của AI Agent. Luồng hoạt động này thường được gọi là Retrieval-Augmented Generation (RAG).
Luồng RAG cơ bản:
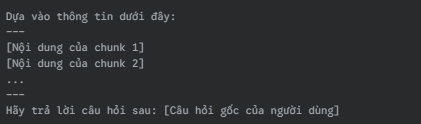
6. LLM Invocation: Prompt hoàn chỉnh này được gửi đến LLM.
7. Final Answer: LLM sẽ tạo ra câu trả lời dựa trên kiến thức của nó và thông tin được cung cấp trong context giúp câu trả lời chính xác và bám sát vào dữ liệu trong bộ nhớ.
Các loại bộ nhớ:
Triển khai bộ nhớ cho AI Agent không phải là một công việc tầm thường, nó là một quy trình kỹ thuật gồm nhiều bước liên kết chặt chẽ. Từ việc xây dựng một Knowledge Ingestion Pipeline vững chắc, lựa chọn chiến lược Chunking thông minh, tạo Embedding chất lượng, cho đến việc sử dụng Vector Store hiệu quả để thực hiện Retrieval, mỗi giai đoạn đều đóng vai trò then chốt quyết định hiệu suất của toàn hệ thống.
Hiểu rõ bản chất của từng bước và các lựa chọn công nghệ đi kèm sẽ giúp anh em developer xây dựng được các AI Agent mạnh mẽ, có khả năng học hỏi và tương tác dựa trên những nguồn kiến thức chuyên biệt, mở ra vô vàn ứng dụng thực tiễn. Chúc anh em code vui!
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
