 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Dữ liệu phi cấu trúc ngày càng chiếm tỷ trọng lớn trong doanh nghiệp, đặc biệt là các file PDF, DOCX hay HTML. Tuy nhiên, việc trích xuất và làm sạch văn bản từ những nguồn này không đơn giản nếu thiếu quy trình. Bài viết dưới đây Bizfly sẽ hướng dẫn bạn từng bước để khai thác dữ liệu phi cấu trúc hiệu quả, phục vụ cho phân tích và ứng dụng AI.
Khác với dữ liệu có cấu trúc (structured data) như trong database SQL (các bảng có cột, kiểu dữ liệu cố định), dữ liệu phi cấu trúc (unstructured data) không có khuôn mẫu rõ ràng, thường ở dạng văn bản, hình ảnh, âm thanh, video. Dưới góc nhìn của Developer, nhóm dữ liệu này có những đặc thù như sau:

Điểm chung của các dạng dữ liệu này là không thể đem phân tích ngay lập tức. Trước khi sử dụng cho báo cáo, nghiên cứu hay các ứng dụng AI, chúng cần được trích xuất nội dung, loại bỏ phần thừa và chuẩn hóa thành văn bản sạch. Đây chính là lý do tại sao xử lý dữ liệu phi cấu trúc được xem là bước khởi đầu quan trọng trong mọi quy trình khai thác dữ liệu hiện đại.
Công cụ phổ biến:
1. Python: PyPDF2, pdfplumber – hỗ trợ đọc text theo trang.
import pdfplumber
with pdfplumber.open("sample.pdf") as pdf:
text = ""
for page in pdf.pages:
text += page.extract_text()
print(text)

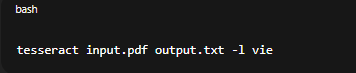
2. OCR (Optical Character Recognition): Tesseract OCR dùng khi PDF là ảnh scan.
tesseract input.pdf output.txt -l vie
Lưu ý khi xử lý PDF:
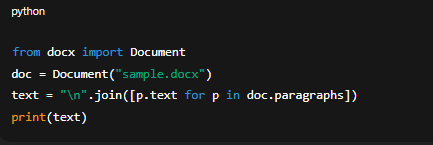
Thư viện đề xuất: python-docx để đọc toàn bộ nội dung, tách tiêu đề (heading), đoạn văn và bảng.
from docx import Document
doc = Document("sample.docx")
text = "\n".join([p.text for p in doc.paragraphs])
print(text)
Ứng dụng thực tế:
Công cụ phổ biến:
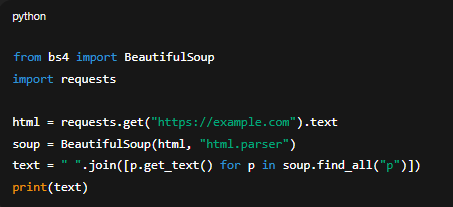
1. BeautifulSoup (Python)
from bs4 import BeautifulSoup
import requestshtml = requests.get("https://example.com").text
soup = BeautifulSoup(html, "html.parser")
text = " ".join([p.get_text() for p in soup.find_all("p")])
print(text)
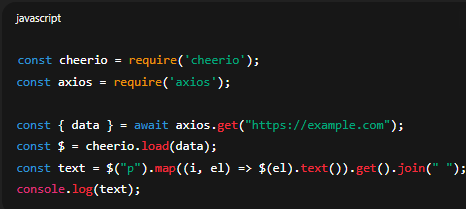
2. Cheerio (Node.js)
const cheerio = require('cheerio');
const axios = require('axios');const { data } = await axios.get("https://example.com");
const $ = cheerio.load(data);
const text = $("p").map((i, el) => $(el).text()).get().join(" ");
console.log(text);
Quy trình:
Ứng dụng thực tế:
Sau khi trích xuất nội dung từ PDF, DOCX hoặc HTML, dữ liệu thô thường chứa rất nhiều ký tự rác, khoảng trắng và thông tin dư thừa. Để có thể sử dụng cho phân tích hoặc đưa vào hệ thống AI, cần tiến hành quy trình làm sạch và chuẩn hóa theo từng bước.
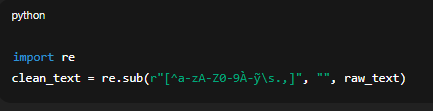
Khi trích xuất từ file, thường xuất hiện các ký tự thừa như xuống dòng, tab, dấu lạ hoặc ký hiệu không mong muốn. Cách làm dùng Regex để lọc và giữ lại ký tự cần thiết (chữ, số, dấu câu). Từ đó kết quả: văn bản gọn gàng, không còn ký tự khó đọc.
import re
clean_text = re.sub(r"[^a-zA-Z0-9À-ỹ\s.,]", "", raw_text)
Văn bản từ nhiều nguồn có thể không đồng nhất về định dạng.
Ví dụ: “Khách HÀNG” → “khách hàng”.
Đây là bước quan trọng để chuẩn bị dữ liệu cho phân tích ngôn ngữ.
Ví dụ: “chạy”, “chạy nhanh”, “chạy bộ” → “chạy”.
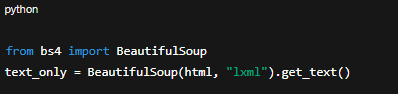
Khi xử lý file HTML hoặc dữ liệu từ web, ngoài nội dung chính còn có nhiều đoạn mã không cần thiết. Cách làm là chỉ giữ lại text, loại bỏ toàn bộ thẻ div, script, style.
Kết quả: chỉ còn nội dung thuần văn bản, dễ đọc và phân tích.
from bs4 import BeautifulSoup
text_only = BeautifulSoup(html, "lxml").get_text()
Sau khi xử lý xong, cần lưu dữ liệu lại dưới dạng chuẩn để dễ tái sử dụng.
Ví dụ: thay vì mở từng PDF, bạn có thể tìm nhanh “khách hàng tiềm năng” trong hàng nghìn file.
Đối với Developer, xử lý dữ liệu phi cấu trúc (PDF, DOCX, HTML) không chỉ là vấn đề đọc text, mà là cả một pipeline gồm: Extract → Clean → Normalize → Export. Sử dụng đúng thư viện và quy trình sẽ giúp tiết kiệm hàng giờ làm thủ công, đồng thời tạo nền tảng cho việc áp dụng AI/ML vào phân tích văn bản. Nếu đang xây dựng hệ thống khai thác dữ liệu hoặc trợ lý AI, đây là bước không thể bỏ qua.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
