 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Embedding đang trở thành nền tảng quan trọng trong mọi ứng dụng AI từ tìm kiếm ngữ nghĩa đến chatbot và hệ thống gợi ý. Với tiếng Việt, nhiều mô hình embedding đã ra đời nhằm tối ưu cho ngữ cảnh ngôn ngữ bản địa. Vậy đâu là mô hình mang lại hiệu năng cao nhất? Bài viết này Bizfly sẽ tổng hợp và so sánh chi tiết các mô hình embedding tiếng Việt phổ biến năm 2025 thông qua bài benchmark thực tế.
Trong các ứng dụng AI hiện đại, embedding là nền tảng giúp máy tính hiểu ngôn ngữ tự nhiên (Natural Language Understanding). Về bản chất, embedding chuyển đổi dữ liệu văn bản như từ, câu, đoạn thành vector số đa chiều, phản ánh mối quan hệ ngữ nghĩa giữa các từ trong không gian toán học.
Ví dụ, trong không gian vector: “học sinh” sẽ nằm gần “giáo viên” hơn là “ô tô”, bởi vì hai từ này có mối liên hệ ngữ nghĩa trong lĩnh vực giáo dục.
Với tiếng Việt, việc huấn luyện embedding lại khó hơn nhiều so với tiếng Anh vì:
Do đó, để đạt độ chính xác cao khi xây dựng các ứng dụng như semantic search, chatbot hay AI Agent, việc lựa chọn đúng mô hình embedding tiếng Việt là yếu tố quyết định.
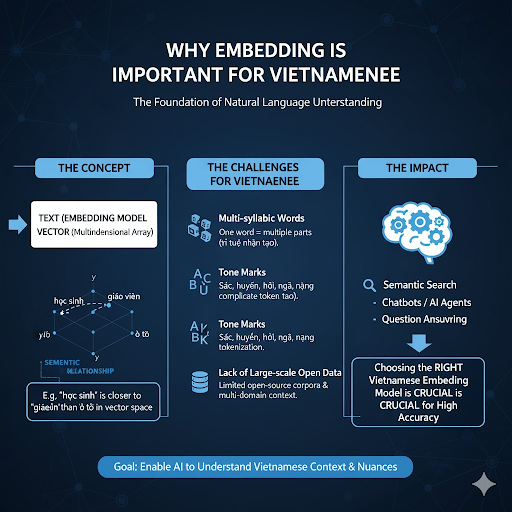
Hiện nay, cộng đồng AI Việt Nam đã phát triển hoặc tinh chỉnh nhiều mô hình embedding, từ cấp độ word-level đến sentence-level giúp biểu diễn ngữ nghĩa tốt hơn cho tiếng Việt. Dưới đây là 4 mô hình nổi bật nhất năm 2025:
| Mô hình | PhoBERT (VinAI Research) | ViEmbedding (VietAI) | bge-vi-base (BAAI Fine-tuned) | sBERT-Vi (Sentence-BERT Việt hóa) |
| Cấu trúc | Phát triển dựa trên kiến trúc RoBERTa | Dựa trên mô hình fastText của Facebook AI | Phiên bản tiếng Việt của mô hình BGE (BAAI General Embedding) | Fine-tune PhoBERT trên tập dữ liệu STS-Vi (Semantic Textual Similarity) |
| Chi tiết | Được huấn luyện trên hơn 20GB dữ liệu tiếng Việt từ Wikipedia, báo chí và mạng xã hội | Hỗ trợ word embedding với khả năng nhận diện từ chưa xuất hiện (OOV – out of vocabulary) | Được fine-tune trên hàng triệu cặp câu hỏi – câu trả lời tiếng Việt | |
| Ưu điểm | Mạnh về hiểu ngữ pháp và ngữ nghĩa từ câu | nhẹ, huấn luyện nhanh, tốc độ xử lý cao | Mạnh trong các tác vụ semantic retrieval, vector search, RAG pipeline | Tối ưu cho việc so sánh độ tương đồng giữa hai câu |
| Ứng dụng | phân tích cảm xúc, phân loại văn bản, chatbot có ngữ cảnh | Phù hợp cho hệ thống cần tốc độ và tiết kiệm tài nguyên như chatbot rule-based hoặc mobile AI app | Là lựa chọn hàng đầu nếu bạn cần embedding phục vụ LLM hoặc AI Agent có khả năng hiểu truy vấn sâu | Kết quả tốt trong hệ thống hỏi đáp (Q&A) và đối thoại ngữ cảnh dài |
Để đảm bảo so sánh khách quan, tất cả các mô hình được đánh giá trong cùng điều kiện:
| Tiêu chí | Mô tả chi tiết |
| Bộ dữ liệu thử nghiệm | ViSim-400, STS-Vi và bộ câu hỏi QA tiếng Việt (UIT) |
| Môi trường chạy | GPU NVIDIA A100, batch size = 32 |
| Các chỉ số đánh giá | - Cosine Similarity Accuracy |
Các mô hình được chạy qua hai loại tác vụ:
| Mô hình | Accuracy (STS-Vi) | MRR@10 (Retrieval) | Tốc độ (câu/s) | Kích thước vector |
| PhoBERT (VinAI) | 0.82 | 0.77 | 1,200 | 768d |
| ViEmbedding (VietAI) | 0.74 | 0.69 | 2,200 | 300d |
| bge-vi-base (BAAI) | 0.88 | 0.84 | 950 | 768d |
| sBERT-Vi (PhoBERT-tuned) | 0.86 | 0.81 | 1,100 | 768d |
Nhận xét tổng hợp:
| Mục tiêu ứng dụng | Mô hình đề xuất | Lý do chọn lựa |
| Chatbot AI / Trợ lý ảo | sBERT-Vi / PhoBERT | Hiểu tốt ngữ nghĩa hội thoại, duy trì mạch ngữ cảnh. |
| Tìm kiếm ngữ nghĩa (Semantic Search) | bge-vi-base | Hiệu năng cao trong tìm kiếm vector và RAG. |
| Phân tích cảm xúc, chủ đề | PhoBERT | Dễ fine-tune, dữ liệu mở nhiều. |
| Ứng dụng nhẹ, tài nguyên thấp | ViEmbedding | Nhỏ gọn, tốc độ cực nhanh. |
Khi triển khai thực tế, bạn có thể dùng bge-vi-base để tạo vector lưu trong ChromaDB hoặc FAISS, sau đó tích hợp vào pipeline RAG. Mỗi khi dữ liệu cập nhật, chỉ cần re-embed phần nội dung mới, không cần huấn luyện lại toàn bộ.
Ví dụ triển khai nhanh (Python Demo)
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("BAAI/bge-vi-base")
sentences = ["Tôi thích học máy.", "Machine learning rất thú vị."]
embeddings = model.encode(sentences, convert_to_tensor=True)similarity = util.cos_sim(embeddings[0], embeddings[1])
print(f"Độ tương đồng ngữ nghĩa: {similarity.item():.4f}")
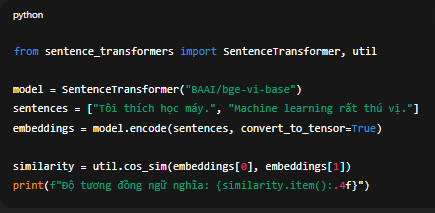
Kết quả cho thấy mô hình bge-vi-base không chỉ dễ tích hợp mà còn cung cấp vector có độ tương đồng chính xác cao, rất hữu ích cho hệ thống retrieval-based chatbot hoặc AI Agent.
Trong thực tế, không ít doanh nghiệp đang kết hợp nhiều mô hình embedding trong cùng pipeline để tối ưu:
Cách tiếp cận này giúp hệ thống vừa nhanh vừa chính xác, phù hợp các dự án lớn như AI Chatbot doanh nghiệp, công cụ tìm kiếm nội bộ, hay nền tảng tri thức tự động (Knowledge Base AI).
Embedding là phần quan nhất của mọi hệ thống AI xử lý ngôn ngữ. Việc chọn sai mô hình có thể khiến pipeline của bạn chậm, nặng, hoặc trả kết quả không chính xác. Ngược lại, chọn đúng mô hình sẽ giúp hệ thống hiểu ngữ nghĩa tiếng Việt sâu hơn, trả lời tự nhiên hơn và tiết kiệm chi phí vận hành.
Trong tương lai gần, sự kết hợp giữa embedding tiếng Việt và mô hình ngôn ngữ lớn (LLM) sẽ tạo nên những AI Agent có khả năng tự học và phản hồi chuẩn xác ngữ cảnh bản địa, mở ra bước tiến mới cho công nghệ AI Việt Nam.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
