 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong các hệ thống AI hiện đại, đặc biệt là khi triển khai mô hình ngôn ngữ lớn (LLM), việc quản lý dữ liệu và xây dựng context đóng vai trò quan trọng để đảm bảo phản hồi chính xác. Một trong những cách tiếp cận phổ biến là sử dụng cơ chế chunked data. Vậy cơ chế xây dựng context từ dữ liệu chunked diễn ra như thế nào? Hãy cùng phân tích luồng xử lý từ Query đến khi Prompt được tạo ra.
Để hiểu rõ cơ chế này, bạn cần nắm 2 yếu tố nền tảng:
Dưới đây là phân tích chi tiết từng bước:
Mọi thứ bắt đầu từ câu hỏi của người dùng. Query có thể là một câu đơn giản như “Chính sách hoàn tiền thế nào?” hoặc phức tạp hơn, liên quan đến nhiều ngữ cảnh.

Query không thể so khớp trực tiếp với dữ liệu văn bản, mà cần chuyển đổi sang dạng số. Đây là lúc embedding model (thường dựa trên Transformer) vào cuộc.
Ví dụ:
Query: "Chính sách hoàn tiền thế nào?"
→ Embedding: [0.123, -0.456, 0.789, ...]
Đây là bước quan trọng giúp tìm đúng dữ liệu cần thiết.
Ví dụ:
Top-3 chunk tìm được:
1. Chunk A (0.92) – nội dung về quy định đổi trả.
2. Chunk B (0.87) – hướng dẫn hoàn tiền.
3. Chunk C (0.83) – thời gian xử lý giao dịch.

Các chunk được chọn lọc sẽ được ghép lại thành một khối context.
Ví dụ context sau khi ghép:
Context:
- Chính sách hoàn tiền áp dụng cho sản phẩm lỗi kỹ thuật trong vòng 7 ngày...
- Quy trình hoàn tiền gồm 3 bước: gửi yêu cầu, xác minh, chuyển khoản…

Khi context đã sẵn sàng, nó được chèn vào prompt cùng với query gốc. Cấu trúc prompt điển hình:
Bạn là trợ lý AI. Dựa trên context sau, hãy trả lời câu hỏi của người dùng.
Context: [nội dung chunk ghép]
Câu hỏi: [query]
Trả lời:
Mô hình LLM nhận được prompt này và tạo ra câu trả lời tự nhiên, sát ngữ cảnh.
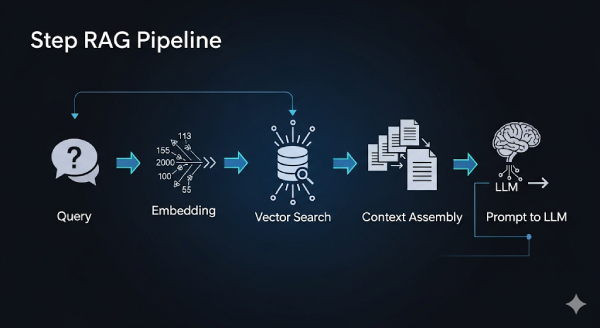
flowchart LR
A[Query] --> B[Embedding]
B --> C[Vector Search]
C --> D[Context Assembly]
D --> E[Prompt vào LLM]
Sơ đồ trên thể hiện rõ pipeline từ Query đến Prompt. Mỗi khâu đều có thể log lại để giám sát: log query sau khi normalize, log embedding dimension, log top-k chunk kèm điểm số, log độ dài token của context. Nhờ vậy, khi kết quả bất thường, dev dễ dàng tìm nguyên nhân.
Cơ chế xây dựng context từ dữ liệu chunked chính là xương sống của các ứng dụng RAG (Retrieval-Augmented Generation). Việc hiểu sâu pipeline Query → Embedding → Search → Context → Prompt giúp dev không chỉ triển khai mà còn tối ưu, debug và scale hệ thống. Trong thời đại AI ngày càng phức tạp, một pipeline rõ ràng, dễ kiểm soát sẽ là lợi thế lớn để nâng trải nghiệm người dùng lên một tầm cao mới.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
