 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



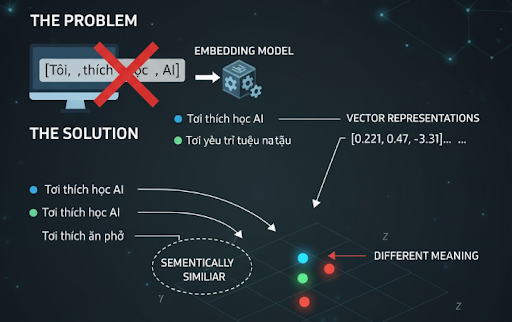
Trong lĩnh vực AI Agent và Machine Learning, Embedding Model được xem là bước cầu nối giúp máy tính hiểu được ngôn ngữ tự nhiên của con người. Bằng cách chuyển đổi dữ liệu thành các vector số học, mô hình Embedding giúp hệ thống xử lý thông tin hiệu quả hơn trong các bài toán như tìm kiếm ngữ nghĩa, gợi ý nội dung hay chatbot thông minh.
Máy tính không thể hiểu ngữ nghĩa “Tôi thích học AI” giống như con người. Nó chỉ thấy các ký tự ["T", "ô", "i", " ", "t", "h", "í", "c", "h", ...]. Nếu bạn muốn máy hiểu hai câu giống nhau về ý nghĩa, bạn cần biểu diễn chúng bằng con số, sao cho các con số của hai câu “gần nhau” nếu nghĩa tương tự.
Embedding Model chuyển mỗi câu, mỗi đoạn văn thành một vector (mảng số thực). Ví dụ:
| Câu | Vector (rút gọn) |
| “Tôi thích học AI” | [0.21, 0.45, -0.32, ...] |
| “Tôi yêu trí tuệ nhân tạo” | [0.22, 0.47, -0.31, ...] |
| “Tôi thích ăn phở” | [-0.88, 0.13, 0.75, ...] |
Embedding Model thường dựa trên Deep Learning, đặc biệt là các mô hình ngôn ngữ như BERT, RoBERTa, T5, GPT,… Cách hoạt động cơ bản:
Từ đó, bạn có thể tính độ tương đồng giữa hai đoạn văn, tìm nội dung giống nhau, hay xây dựng hệ thống hỏi đáp hiểu ngữ cảnh.
Nếu bạn là DEV, đây là phần thực tế nhất:
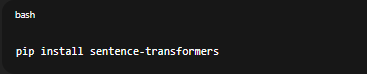
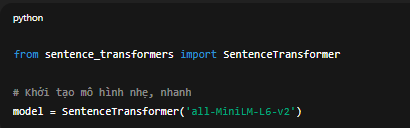
Chúng ta sẽ dùng Sentence-Transformers như một thư viện Python phổ biến giúp chuyển câu thành vector một cách cực kỳ đơn giản.
pip install sentence-transformers
from sentence_transformers import SentenceTransformer
# Khởi tạo mô hình nhẹ, nhanh
model = SentenceTransformer('all-MiniLM-L6-v2')
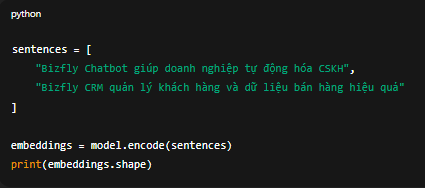
sentences = [
"Bizfly Chatbot giúp doanh nghiệp tự động hóa CSKH",
"BizCRM quản lý khách hàng và dữ liệu bán hàng hiệu quả"
]embeddings = model.encode(sentences)
print(embeddings.shape)
Output: (2, 384)
Tức là: Có 2 câu, mỗi câu được chuyển thành vector 384 chiều
print(embeddings[0][:10]) # In 10 phần tử đầu tiên

Ví dụ: [0.043, -0.121, 0.366, -0.081, 0.092, 0.151, -0.084, 0.255, ...]
Đây chính là “vector ngữ nghĩa” biểu diễn cho câu đầu tiên.
Dùng Cosine Similarity để đo mức độ “gần nhau”:
from sklearn.metrics.pairwise import cosine_similarity
score = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
print("Độ tương đồng:", round(score, 3))
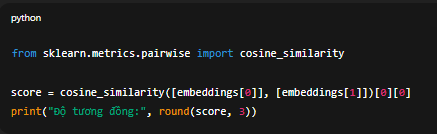
Kết quả: Độ tương đồng: 0.89. Điểm càng gần 1.0 → hai câu càng có nghĩa tương tự.
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')

Model này hỗ trợ hơn 50 ngôn ngữ, bao gồm tiếng Việt, nên phù hợp khi bạn xử lý dữ liệu nội dung trong nước (ví dụ chatbot tư vấn, phân tích phản hồi khách hàng...).
Embedding được ứng dụng rất rộng trong thế giới AI – và nhiều thứ bạn đang dùng hằng ngày đều dựa vào nó:
| Ứng dụng | Cách dùng Embedding |
| Tìm kiếm ngữ nghĩa (Semantic Search) | So sánh vector câu hỏi và tài liệu để tìm nội dung phù hợp nhất |
| Chatbot AI (RAG) | Biến câu hỏi & tài liệu thành vector → tìm đoạn liên quan → gửi cho LLM |
| Gợi ý sản phẩm / bài viết | Tìm sản phẩm có vector gần với vector của người dùng |
| Phân nhóm dữ liệu | Dùng clustering (KMeans) trên các vector embedding |
| Phân tích cảm xúc | Vector hóa câu → phân loại “tích cực / tiêu cực” |
Ví dụ:
Bizfly ứng dụng Embedding trong:
Nếu bạn đang xây chatbot AI hoặc Q&A system, Embedding là bước nền tảng trong RAG (Retrieval-Augmented Generation). Pipeline cơ bản:
Sơ đồ pipeline:
User Question → Embedding → Semantic Search → Retrieve Top-k → LLM → Response
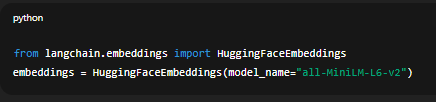
Nếu bạn dùng LangChain hoặc LlamaIndex, Sentence-Transformers có thể tích hợp trực tiếp:
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
| Tên mô hình | Kích thước vector | Đặc điểm |
| all-MiniLM-L6-v2 | 384 | Nhẹ, tốc độ nhanh, chính xác tốt |
| multi-qa-MiniLM-L6-cos-v1 | 384 | Tối ưu cho câu hỏi–trả lời |
| paraphrase-multilingual-MiniLM-L12-v2 | 384 | Hỗ trợ tiếng Việt, đa ngôn ngữ |
| sentence-t5-base | 768 | Chất lượng cao, dùng cho NLP chuyên sâu |
| e5-large-v2 | 1024 | Chuẩn cho Semantic Search ở quy mô lớn |
Embedding Model không chỉ là “một thuật ngữ AI” mà là nền móng của hầu hết hệ thống thông minh ngày nay. Nó giúp máy tính hiểu dữ liệu bằng ngữ nghĩa, mở đường cho hàng loạt ứng dụng như chatbot, RAG, semantic search, recommendation engine,…
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
