 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Nếu bạn từng triển khai hệ thống RAG hay xây dựng context cho mô hình ngôn ngữ lớn, chắc chắn đã gặp tình huống dữ liệu trả về từ cơ sở vector có rất nhiều đoạn nghe có vẻ gần gũi nhưng thực ra không liên quan. Đó chính là thông tin nhiễu. Bài viết này sẽ hướng dẫn cách áp dụng Cross-Encoder để loại bỏ thông tin nhiễu khi xây context giúp context gọn nhẹ, chính xác và hữu ích hơn cho mô hình.
Trong pipeline của RAG, luồng xử lý cơ bản thường là:
Người dùng đặt câu hỏi → Truy vấn embedding → Tìm kiếm trong cơ sở vector → Lấy top-k đoạn văn → Xây dựng context → Đưa vào mô hình.
Nghe có vẻ trơn tru, nhưng thực tế kết quả trả về không phải lúc nào cũng chuẩn. Cơ sở vector chỉ so sánh độ gần trong không gian embedding, chứ chưa thật sự hiểu nội dung sâu sắc. Kết quả là bạn nhận được nhiều đoạn gần giống nhưng chẳng mấy liên quan. Điều này dẫn đến một loạt vấn đề:
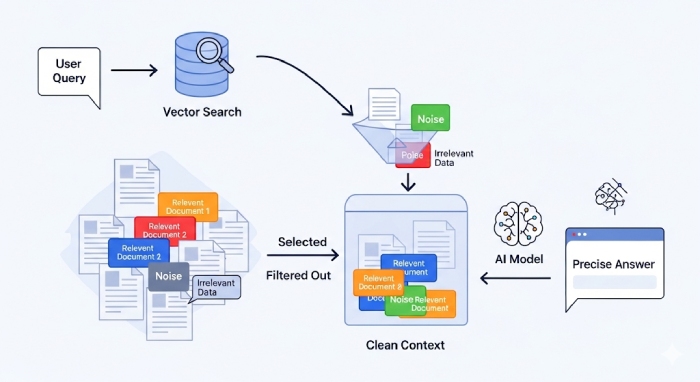
Bi-Encoder vốn quen thuộc trong vector search, nhưng nó chỉ mã hoá truy vấn và tài liệu riêng rẽ, sau đó so sánh điểm gần nhau. Tốc độ nhanh, nhưng độ chính xác có giới hạn.
Cross-Encoder thì khác. Nó nhận cả truy vấn và đoạn văn cùng lúc, tính toán trực tiếp mức độ liên quan. Điều này giống như một người đọc cả câu hỏi lẫn đoạn văn, rồi mới quyết định xem chúng có thực sự liên quan không. Nhờ vậy, kết quả sắp xếp lại chính xác hơn nhiều. Trong thực tế, dev thường kết hợp cả hai:
Cách làm này vừa tiết kiệm, vừa hiệu quả.
Quy trình cơ bản sẽ có các bước sau:
Ví dụ code đơn giản trong Python:

from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')pairs = [(query, doc) for doc in retrieved_docs]
scores = model.predict(pairs)
ranked = sorted(zip(retrieved_docs, scores), key=lambda x: x[1], reverse=True)
final_context = [doc for doc, score in ranked[:5]]
Loại bỏ thông tin nhiễu khi xây context là bước quan trọng giúp hệ thống RAG hoạt động ổn định và mang lại kết quả tin cậy. Cross-Encoder chính là công cụ lọc tinh, đảm bảo chỉ những đoạn liên quan nhất được đưa vào mô hình. Kết hợp Bi-Encoder để tìm nhanh và Cross-Encoder để sắp xếp lại, dev có thể xây dựng pipeline vừa nhanh, vừa chính xác, vừa tiết kiệm chi phí.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
