 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong triển khai RAG (Retrieval-Augmented Generation), cách chia nhỏ dữ liệu (chunking) ảnh hưởng trực tiếp đến độ chính xác và hiệu suất. Có nhiều phương pháp chunking khác nhau như Token-Based và Semantic-Based, mỗi cách đều có ưu – nhược điểm riêng. Bài viết này sẽ cung cấp một bài benchmark thực tế, so sánh hiệu quả của các phương pháp chunking trong việc tối ưu kết quả truy vấn AI.
Trong RAG, dữ liệu gốc thường có dung lượng rất lớn như báo cáo, tài liệu kỹ thuật, sách hoặc lịch sử giao dịch khách hàng. Nếu đưa nguyên văn toàn bộ dữ liệu vào mô hình, chi phí token sẽ cực kỳ cao và dễ vượt quá giới hạn đầu vào. Vì vậy, chunking giúp:
Một chunk được cắt “chuẩn” sẽ giúp AI Agent hiểu đầy đủ ý nghĩa, hạn chế tình trạng trả lời mơ hồ hoặc thiếu sót. Đây là lý do chunking thường được coi là “bí quyết” quyết định chất lượng RAG.
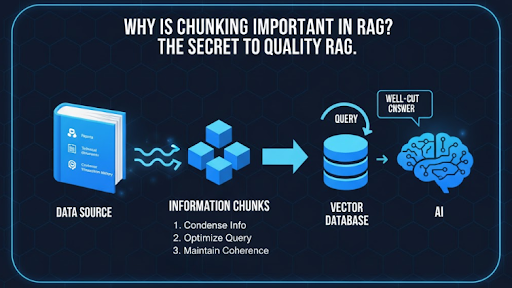
Trước khi nhúng dữ liệu vào vector database và dùng trong pipeline RAG, việc chia nhỏ dữ liệu (chunking) là bước cực kỳ quan trọng. Mỗi cách chunk khác nhau sẽ ảnh hưởng đến độ chính xác của retrieval (tìm kiếm thông tin) và generation (tạo câu trả lời).
Hiện nay có ba hướng chunking phổ biến nhất mà dev thường dùng khi xây dựng hệ thống RAG: Token-Based, Semantic-Based và Hybrid Chunking. Dưới đây là cách chúng hoạt động, ưu nhược điểm và tình huống nên chọn.
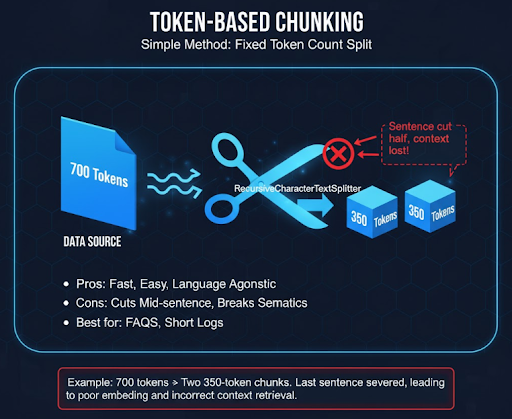
Phương pháp đơn giản nhất là chia văn bản theo số token cố định (thường 300–500). Hệ thống đếm token và cắt khi đạt ngưỡng, ví dụ bằng RecursiveCharacterTextSplitter trong LangChain. Ưu điểm là nhanh, dễ kiểm soát, không phụ thuộc ngôn ngữ. Nhưng vì cắt cơ học nên dễ chia giữa câu, khiến ngữ nghĩa bị đứt đoạn. Dữ liệu ngắn như FAQ hoặc log ngắn phù hợp nhất.
Ví dụ: đoạn 700 tokens bị tách thành 2 phần 350–350, câu cuối bị cắt đôi, dẫn đến embedding rời rạc và retriever dễ trả về sai ngữ cảnh.
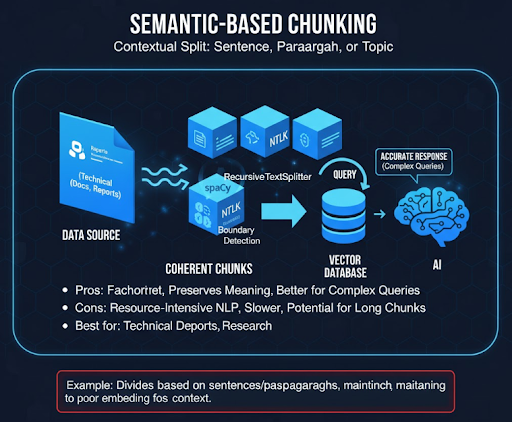
Thay vì đếm token, cách này tách dựa theo ngữ nghĩa: câu, đoạn, hoặc chủ đề. Dev thường dùng spaCy, NLTK hay VnCoreNLP để phát hiện boundary hợp lý. Chunk được tạo ra thường dài hơn nhưng giữ trọn mạch ý giúp model hiểu chính xác hơn khi truy vấn phức tạp.
Nhược điểm là tốn tài nguyên NLP, tốc độ xử lý chậm, đôi khi chunk quá dài vượt token limit. Phù hợp với tài liệu kỹ thuật, báo cáo hoặc research có cấu trúc rõ.
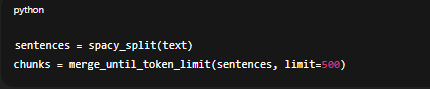
Là sự kết hợp giữa hai hướng trên. Hệ thống tách theo ngữ nghĩa trước, sau đó nếu đoạn vượt ngưỡng token thì mới cắt tiếp. Vừa giữ được ý nghĩa đầy đủ, vừa đảm bảo hiệu năng.
Đây là cách hầu hết team AI engineer dùng trong production RAG vì cân bằng giữa accuracy và latency. Ví dụ code đơn giản:
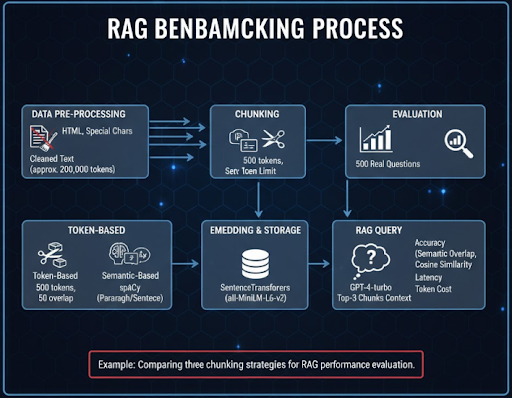
Để đánh giá mức độ ảnh hưởng của phương pháp chunking đến hiệu suất của RAG pipeline, chúng tôi thực hiện một benchmark nhỏ trên tập dữ liệu kỹ thuật thực tế. Mục tiêu là đo lường độ chính xác truy vấn (retrieval accuracy), thời gian phản hồi (latency) và chi phí token (token usage) khi sử dụng ba phương pháp: Token-Based, Semantic-Based, và Hybrid Chunking.
Bộ dữ liệu gồm 1.000 cặp hỏi – đáp (Q&A pair) được trích từ tài liệu kỹ thuật, API docs và báo cáo nội bộ. Tất cả câu hỏi đều có ground truth để so sánh kết quả.
1. Tiền xử lý dữ liệu: Văn bản gốc được làm sạch: loại bỏ HTML, ký tự đặc biệt, chuẩn hóa format. Chúng tôi giới hạn nội dung khoảng 200.000 tokens để mô phỏng dataset vừa phải.
2. Chunking: Ba pipeline được áp dụng song song:
3. Embedding & lưu trữ: Tất cả chunk được nhúng bằng mô hình SentenceTransformers (all-MiniLM-L6-v2) và lưu trong ChromaDB để đảm bảo tính nhất quán.
4. Truy vấn RAG: 500 câu hỏi thực tế được gửi vào pipeline. Mỗi câu truy vấn lấy top-3 chunk có độ tương đồng cao nhất. Sau đó, chúng tôi dùng mô hình GPT-4-turbo để tạo câu trả lời dựa trên context.
5. Đánh giá: Độ chính xác được tính theo mức độ trùng khớp semantic giữa câu trả lời và ground truth, đo bằng cosine similarity giữa embedding của hai đoạn. Ngoài ra, chúng tôi cũng đo latency trung bình và token cost trong quá trình inference.
Token-Based đạt độ chính xác trung bình ~78%. Với các câu hỏi đơn giản, ví dụ “Định nghĩa WebSocket là gì?”, pipeline hoạt động ổn vì chunk ngắn dễ khớp. Nhưng khi truy vấn cần ngữ cảnh (“Vì sao WebSocket phù hợp cho ứng dụng real-time?”), câu trả lời thường thiếu phần giải thích hoặc sai lệch vì mất ngữ nghĩa giữa các chunk.
Semantic-Based cải thiện rõ, đạt ~85% độ chính xác. Vì các đoạn được giữ nguyên ranh giới câu, mô hình có đủ ngữ cảnh để suy luận. Với câu hỏi “Làm thế nào để retry request khi API trả lỗi 429?”, RAG có thể lấy đúng đoạn mô tả cơ chế throttle và retry policy. Tuy nhiên, độ trễ trung bình cao hơn 1.6 lần do số token mỗi chunk lớn hơn, dẫn đến embedding và inference chậm hơn.
Hybrid Chunking là phương pháp hiệu quả nhất trong thử nghiệm, đạt ~88% độ chính xác. Nhờ chia hợp lý giữa ngữ nghĩa và token count, pipeline vừa không mất mạch ngữ cảnh, vừa không quá nặng nề khi xử lý. Latency trung bình chỉ cao hơn Token-Based khoảng 12%, nhưng độ chính xác tăng gần 10%.
| Phương pháp | Accuracy | Latency trung bình | Token cost (tương đối) |
| Token-Based | 78% | 1.0x | 1.0x |
| Semantic-Based | 85% | 1.6x | 1.5x |
| Hybrid Chunking | 88% | 1.12x | 1.2x |
Nhìn từ kết quả, Token-Based có lợi thế tốc độ và chi phí thấp, nhưng đánh đổi độ chính xác. Semantic-Based cho precision cao hơn rõ rệt, song tốn compute. Hybrid mang lại điểm cân bằng hợp lý, chính xác cao, vẫn giữ throughput ổn định, phù hợp cho môi trường production.
Không có câu trả lời duy nhất, mà phụ thuộc vào đặc điểm dữ liệu và mục tiêu hệ thống. Token-Based phù hợp khi bạn cần build nhanh, dữ liệu ngắn và ít ngữ cảnh, chẳng hạn chatbot FAQ, log tra cứu, hay hệ thống cần tốc độ cao với budget hạn chế. Bạn chỉ cần vài dòng code với LangChain là pipeline chạy được ngay.

Semantic-Based là lựa chọn khi bạn xử lý dữ liệu dạng dài và liên kết logic, ví dụ tài liệu hướng dẫn kỹ thuật, báo cáo R&D hoặc nghiên cứu học thuật. Nó giúp RAG hiểu rõ hơn các mối quan hệ giữa câu, đoạn và chủ đề, tăng chất lượng câu trả lời, đặc biệt với câu hỏi “why” và “how”.
Hybrid Chunking là lựa chọn “production-grade”. Trong hầu hết dự án doanh nghiệp, bạn sẽ gặp dữ liệu không đồng nhất: văn bản ngắn, dài, log, tài liệu PDF, Markdown, v.v. Hybrid có thể xử lý tất cả mà không cần thiết lập thủ công từng loại.
Nếu bạn đang phát triển hệ thống RAG thực tế, lời khuyên là hãy benchmark cả ba cách trên dataset của bạn. Không có phương pháp “tốt nhất toàn cục”, chỉ có cách tối ưu nhất cho dữ liệu và hạ tầng cụ thể của bạn.
Việc chọn phương pháp chunking không có công thức cố định, mà phụ thuộc vào dữ liệu, bài toán và tài nguyên hệ thống. Qua benchmark trên, có thể thấy Semantic-Based và Hybrid mang lại kết quả tốt hơn trong hầu hết trường hợp. Tuy nhiên, Token-Based vẫn hữu ích trong môi trường cần tốc độ và tối ưu chi phí.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
