 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong xử lý ngôn ngữ tự nhiên (NLP) và các ứng dụng AI, việc chia nhỏ dữ liệu văn bản thành các đoạn hợp lý là bước quan trọng để tối ưu hóa quá trình huấn luyện. Một trong những kỹ thuật phổ biến hiện nay là Token-Based Chunking – Cắt dữ liệu theo số token, thường được triển khai thông qua công cụ RecursiveCharacterTextSplitter trong LangChain. Bài viết này sẽ giúp bạn hiểu rõ cơ chế, cách sử dụng và demo chi tiết.
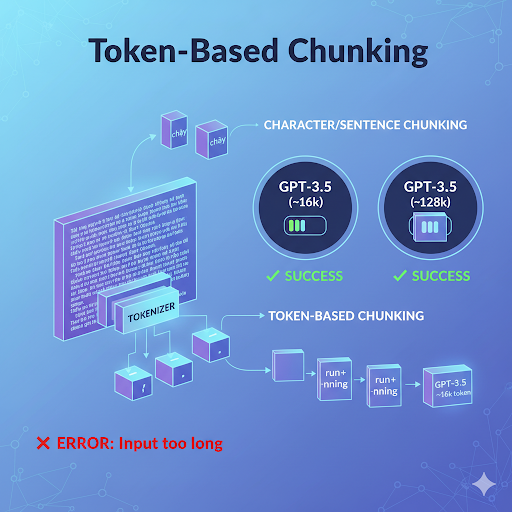
Trong quá trình xây dựng ứng dụng AI, dữ liệu văn bản thường quá dài để đưa vào một lần cho mô hình ngôn ngữ (LLM) xử lý. Đây là lý do chunking – kỹ thuật chia nhỏ dữ liệu – trở nên cần thiết. Khác với cách cắt theo số ký tự hay câu, Token-Based Chunking chia văn bản dựa trên số token. Điều này quan trọng bởi:
Nhờ cắt theo token, bạn kiểm soát chính xác dung lượng dữ liệu, tránh lỗi “Input too long” khi gọi API, đồng thời tối ưu chi phí xử lý.
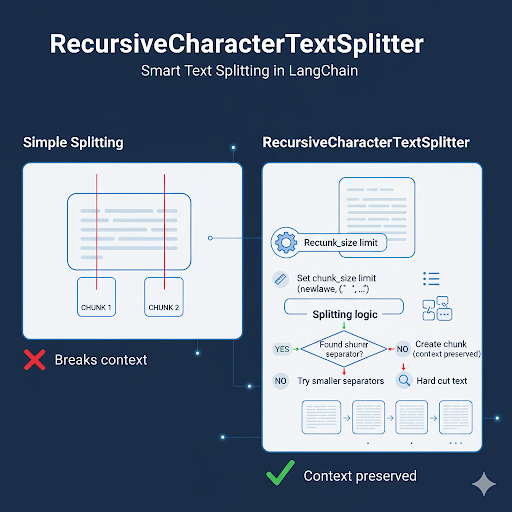
RecursiveCharacterTextSplitter là công cụ mạnh mẽ trong LangChain, giúp cắt văn bản một cách thông minh. Thay vì “cắt phăng” văn bản tại số token cố định, nó tìm điểm dừng hợp lý như xuống dòng, dấu chấm câu, khoảng trắng… trước khi buộc phải cắt cứng. Cơ chế hoạt động:
Nhờ vậy, chunk dữ liệu vừa đủ dài, vừa giữ được mạch ngữ nghĩa.
Khi sử dụng RecursiveCharacterTextSplitter, bạn có thể tinh chỉnh nhiều tham số để điều khiển cách văn bản được chia nhỏ. Việc hiểu rõ ý nghĩa của từng tham số giúp bạn cắt dữ liệu tối ưu cho mục tiêu huấn luyện AI, tìm kiếm tri thức (RAG) hay triển khai chatbot.
Định nghĩa: Xác định số token tối đa cho mỗi đoạn văn bản sau khi cắt.
Ý nghĩa: Nếu đặt quá lớn, đoạn có thể vượt ngưỡng mô hình → lỗi khi gọi API. Nếu quá nhỏ, dữ liệu bị chia vụn, mất mạch ngữ cảnh.
Ví dụ: chunk_size=500 → mỗi đoạn có độ dài tối đa 500 token.
Cách làm tốt nhất:
Định nghĩa: Quy định số token được lặp lại ở đoạn kế tiếp để duy trì ngữ cảnh.
Ý nghĩa: Nếu không có overlap, câu ở cuối đoạn này và đầu đoạn sau có thể bị mất liên kết → AI trả lời thiếu chính xác.
Ví dụ:
chunk_size=500,
chunk_overlap=50→ đoạn 1 gồm token 1–500, đoạn 2 sẽ bắt đầu từ token 451 thay vì 501.
Cách làm tốt nhất:
Định nghĩa: Là danh sách ký tự mà splitter sẽ thử trước khi buộc phải cắt cứng văn bản.
Ý nghĩa: Giúp chunk tự nhiên, tránh chia văn bản giữa chừng trong từ hoặc câu.
Ví dụ: separators=["\n\n", "\n", ".", " ", ""] → Trong đó: \n\n: cắt theo đoạn văn.
\n: cắt theo dòng.
.: cắt ở cuối câu.
" ": cắt ở khoảng trắng.
"": fallback cuối cùng (cắt cứng).
Cách làm tốt nhất:
Định nghĩa: Hàm dùng để đo chiều dài văn bản dựa trên token thay vì ký tự.
Ý nghĩa: Vì LLM xử lý theo token, nên cần tokenizer chuẩn (ví dụ tiktoken) để tính đúng số lượng.
Ví dụ:
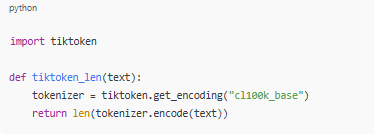
import tiktoken
def tiktoken_len(text):
tokenizer = tiktoken.get_encoding("cl100k_base")
return len(tokenizer.encode(text))
Cách làm tốt nhất:
Định nghĩa: Tham số cho phép bạn giữ lại ký tự phân tách (ví dụ dấu chấm câu, xuống dòng) trong kết quả sau khi cắt.
Ý nghĩa: Nếu đặt quá lớn, đoạn có thể vượt ngưỡng mô hình → lỗi khi gọi API. Nếu quá nhỏ, dữ liệu bị chia vụn, mất mạch ngữ cảnh.
Ví dụ: keep_separator=True → mỗi chunk vẫn giữ dấu . hoặc \n.
Ứng dụng: Giúp văn bản sau khi chunk vẫn đọc mượt mà, hữu ích cho chatbot hoặc hiển thị trực tiếp cho người dùng.
Định nghĩa: Nếu True, splitter sẽ trả thêm index của chunk trong văn bản gốc.
Ví dụ: add_start_index=True → mỗi chunk sẽ có thêm metadata {"start_index": 1234}.
Ứng dụng: Hữu ích cho RAG, khi bạn cần map chunk → vị trí gốc trong tài liệu.
Định nghĩa: Loại bỏ khoảng trắng ở đầu và cuối chunk sau khi cắt.
Ví dụ: strip_whitespace=True
Ý nghĩa: Giữ cho dữ liệu sạch, tránh lỗi khi indexing hoặc embedding.
Tổng kết lại cuối cùng anh em dev chỉ cần hiểu như sau:
Dưới đây là ví dụ thực tế bằng Python:
from langchain.text_splitter import RecursiveCharacterTextSplitter
import tiktoken# Định nghĩa hàm đếm token
def tiktoken_len(text):
tokenizer = tiktoken.get_encoding("cl100k_base")
return len(tokenizer.encode(text))# Cấu hình splitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
length_function=tiktoken_len,
separators=["\n\n", "\n", ".", " ", ""]
)# Văn bản demo
text = """Token-Based Chunking giúp tối ưu dữ liệu đầu vào cho AI Agent...
Nó đảm bảo văn bản không vượt quá giới hạn token và vẫn giữ ngữ cảnh tự nhiên."""chunks = splitter.split_text(text)
# In kết quả
for i, chunk in enumerate(chunks):
print(f"--- Chunk {i+1} ({len(chunk)} ký tự) ---")
print(chunk)

Kết quả:
| Tiêu chí | Cắt theo ký tự | Cắt theo token (Token-Based) |
| Đơn vị cắt | Số thứ tự | Số token (theo tokenizer LLM) |
| Tính chính xác với LLM | Không đảm bảo | Chính xác tuyệt đối |
| Khả năng tối ưu chi phí | Thấp | Cao |
| Ngữ cảnh giữ lại | Có thể bị cắt giữa từ | Giữ nguyên ngữ nghĩa |
| Ứng dụng | Văn bản tĩnh, log đơn giản | AI, NLP, RAG, Chatbot |
Token-Based Chunking mang lại nhiều lợi ích thiết thực khi xử lý dữ liệu cho AI, từ việc đảm bảo văn bản không vượt giới hạn mô hình cho đến nâng cao hiệu suất và tính chính xác trong truy vấn.
Token-Based Chunking – Cắt dữ liệu theo số token là kỹ thuật quan trọng trong xây dựng ứng dụng AI và NLP hiện đại. Với sự hỗ trợ của RecursiveCharacterTextSplitter, lập trình viên có thể dễ dàng triển khai việc chia nhỏ văn bản, kiểm soát kích thước token và đảm bảo chất lượng dữ liệu đầu vào. Khi nắm vững các tham số như chunk_size, chunk_overlap và separators, bạn sẽ tối ưu được hiệu suất và độ chính xác của mô hình.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
