 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong hệ thống Retrieval-Augmented Generation, chất lượng embedding phụ thuộc không chỉ vào mô hình mà còn vào cách bạn “chunk” dữ liệu. Gần đây, chiến lược Agent Chunking được xem là bước tiến mới giúp tạo ra vector embedding chính xác và bám ngữ cảnh hơn. Bài viết này Bizfly sẽ đi sâu phân tích cơ chế hoạt động, vai trò và cách tối ưu Agent Chunking trong pipeline embedding dữ liệu.
Chunking là quá trình chia nhỏ nội dung lớn (văn bản, hội thoại, code, tài liệu kỹ thuật, v.v.) thành những đơn vị nhỏ hơn (chunk) trước khi đưa vào mô hình embedding để tạo vector.
Nếu bạn đưa một tài liệu dài 10.000 từ vào mô hình embedding, nó sẽ vượt quá giới hạn token của mô hình và mất mạch ngữ nghĩa. Vì vậy, ta phải chia nhỏ nhưng chia như thế nào lại ảnh hưởng trực tiếp đến ngữ nghĩa mà vector học được.
| Kích thước chunk | Ưu điểm | Nhược điểm |
| Quá ngắn (100–200 token) | Dễ index, nhanh retriever | Mất ngữ cảnh, vector rời rạc |
| Quá dài (800–1500 token) | Giữ ngữ cảnh tốt | Vector "nhiễu", embedding bị trộn nhiều chủ đề |
| Tối ưu (300–600 token) | Cân bằng giữa ngữ cảnh và tính đặc trưng | Cần tinh chỉnh theo loại dữ liệu |
Một chunk tốt phải giúp mô hình hiểu ý nghĩa trọn vẹn của một đoạn nội dung, nhưng không dư thừa đến mức chứa nhiều chủ đề khác nhau.
Agent Chunking là phương pháp chia nhỏ dữ liệu theo vai trò (role) hoặc nhiệm vụ cụ thể (task) của từng Agent trong hệ thống. Thay vì chia toàn bộ dữ liệu theo token hoặc câu, hệ thống sẽ dùng tư duy ngữ cảnh của từng Agent để xác định ranh giới chunk.
Ví dụ:
Kết quả là, mỗi vector embedding được tạo ra mang ngữ nghĩa riêng theo vai trò của AI Agent, giúp hệ thống retrieval (tìm kiếm vector) chính xác và có ngữ cảnh hơn.
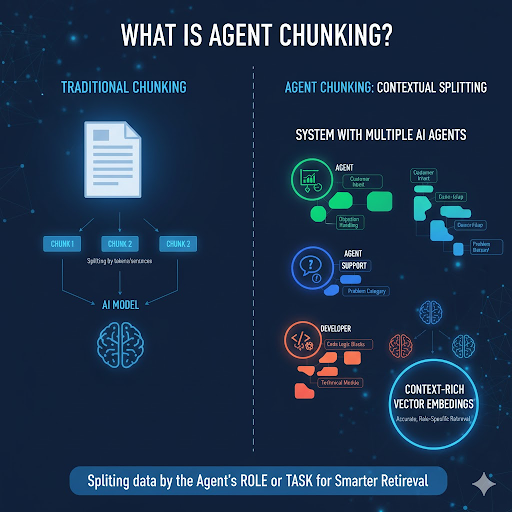
Quy trình triển khai Agent Chunking có thể hình dung như sau:
Dữ liệu gốc
↓
Phân loại theo Agent
↓
Xác định chiến lược chunk riêng
↓
Sinh embedding bằng mô hình phù hợp
↓
Lưu vector vào Vector Database
Ví dụ code (Python / LangChain style)
agents = {
"sales": {"strategy": "intent_chunking", "embedding_model": "text-embedding-3-large"},
"support": {"strategy": "qa_pair_chunking", "embedding_model": "text-embedding-3-small"},
"developer": {"strategy": "code_block_chunking", "embedding_model": "code-embedding-ada"}
}for role, config in agents.items():
docs = load_docs_by_role(role)
chunks = agent_chunk(docs, strategy=config["strategy"])
vectors = embed(chunks, model=config["embedding_model"])
store_in_vector_db(vectors, namespace=role)
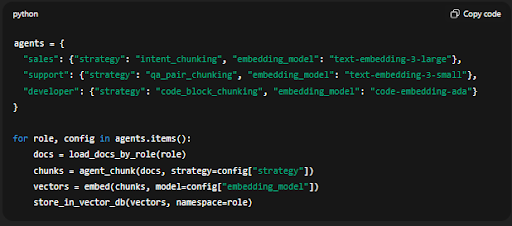
Cách này giúp mỗi Agent có vùng vector riêng biệt (namespace) trong vector DB, đảm bảo dữ liệu truy vấn của Agent Sales không bị lẫn với Support hay Tech.
| Loại chunking | Cách hoạt động | Ưu điểm | Hạn chế |
| Token-based | Chia theo số token (ví dụ: 500 token) | Dễ áp dụng, nhanh | Mất ngữ cảnh, cắt ngang câu |
| Recursive chunking | Tách theo đoạn, câu, tiêu đề | Giữ được mạch nội dung cơ bản | Khó xử lý dữ liệu phi cấu trúc |
| Semantic chunking | Dựa trên ngữ nghĩa (cosine similarity) | Bảo toàn ý nghĩa | Tốn tài nguyên tính toán |
| Agent chunking | Chia theo logic nghiệp vụ, role hoặc intent | Giữ ngữ cảnh chuyên biệt, tối ưu cho multi-agent | Cần training hoặc rule riêng cho từng Agent |
Như vậy, Agent Chunking là bước tiến tự nhiên của semantic chunking, nhưng có định hướng hành vi cụ thể phù hợp với các hệ thống AI đa vai trò (multi-agent orchestration).
Một chiến lược Agent Chunking tốt sẽ giúp:
Ví dụ minh họa:
| Chiến lược | Recall@5 | MRR | Accuracy |
| Token-based | 0.68 | 0.54 | 78% |
| Semantic Chunking | 0.75 | 0.63 | 84% |
| Agent Chunking | 0.83 | 0.71 | 91% |
Khi vector được sinh ra từ đúng “vai trò” của Agent, mô hình retrieval sẽ ít phải đoán ngữ cảnh, từ đó tăng độ chính xác tổng thể.
Agent Chunking giúp đảm bảo khi người dùng hỏi:
“Làm sao để xử lý khi khách hàng từ chối nhận hàng?”
→ Agent “Sales” sẽ truy xuất đúng vector từ namespace “sales”, thay vì đọc tài liệu kỹ thuật.
Các Agent như “Analyzer”, “Planner”, “Executor” có thể chunk dữ liệu khác nhau:
Analyzer → chia theo insight logic
Planner → chia theo quy trình
Executor → chia theo hành động (action block)
BizChatAI có thể tích hợp Agent Chunking để tạo bộ nhớ hội thoại theo từng vai trò:
Điều này giúp hệ thống hiểu “người nói – ngữ cảnh – mục tiêu”, từ đó phản hồi chính xác và tự nhiên hơn.
Để đánh giá chất lượng embedding sau khi áp dụng Agent Chunking, có thể dùng các chỉ số:
Ví dụ kết quả test:
Before Agent Chunking: Recall@5 = 0.71 | MRR = 0.62 | Latency = 380ms
After Agent Chunking: Recall@5 = 0.83 | MRR = 0.71 | Latency = 350ms

→ Vector retrieval nhanh hơn, chính xác hơn và nhất quán theo vai trò.
Agent Chunking là một trong những kỹ thuật quan trọng giúp AI Agent trở nên hiểu ngữ cảnh và chuyên biệt hóa hơn. Thay vì chỉ tập trung vào mô hình embedding, việc xây dựng chiến lược chunk phù hợp cho từng loại dữ liệu sẽ tạo ra vector giàu ngữ nghĩa và tăng hiệu quả hệ thống RAG. Trong tương lai, Agent Chunking có thể được kết hợp với Dynamic Memory Routing cho phép AI tự xác định chiến lược chunk tối ưu theo mục tiêu hội thoại.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
