 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
Để dành mua sau (0 sản phẩm)
Không có sản phẩm nào trong danh sách để dành mua sau của bạn!
 Đỗ Minh Đức
Đỗ Minh Đức



Trong kỷ nguyên dữ liệu bùng nổ, việc đồng bộ dữ liệu từ nhiều nguồn về một hệ thống AI trở thành nền tảng quan trọng để xây dựng các mô hình thông minh. Một kiến trúc pipeline dữ liệu (ETL) đơn giản không chỉ giúp làm sạch và tổ chức dữ liệu, mà còn mở đường cho các ứng dụng Retrieval Augmented Generation (RAG) hoạt động chính xác và hiệu quả hơn.
Khi xây dựng một hệ thống AI, dữ liệu không chỉ đến từ một nguồn duy nhất. Developer thường phải xử lý dữ liệu rải rác ở:
Nếu không có pipeline xử lý, developer sẽ gặp các vấn đề: dữ liệu bị trùng lặp, định dạng không đồng nhất, text lẫn nhiều ký tự rác, hoặc thiếu metadata để AI hiểu ngữ cảnh.
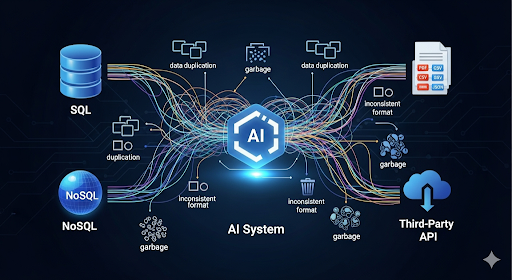
Để xây dựng một hệ thống Retrieval Augmented Generation (RAG) hoạt động hiệu quả, developer cần một pipeline dữ liệu chặt chẽ nhằm đảm bảo dữ liệu đi qua các bước trích xuất – chuyển đổi – nạp vào hệ thống một cách tối ưu. Đây là quá trình quan trọng giúp AI có ngữ cảnh đầy đủ và hạn chế tình trạng “hallucination”.
Ở giai đoạn này, nhiệm vụ chính là kết nối và lấy dữ liệu từ các nguồn khác nhau, càng tự động hóa càng tốt để giảm thao tác thủ công.

Từ cơ sở dữ liệu:
Developer có thể dùng SQLAlchemy trong Python để kết nối đa dạng CSDL quan hệ như MySQL, PostgreSQL, SQL Server. Nếu dùng Node.js, có thể chọn Prisma hoặc Sequelize để truy vấn thuận tiện hơn.
Từ file tài liệu:
Từ API:
Kết nối REST hoặc GraphQL thông qua requests/httpx (Python) hoặc axios (Node.js). Quản lý token/bí mật bằng .env file và dùng thư viện dotenv để tránh hard-code key vào source.
Đây là giai đoạn quyết định chất lượng dữ liệu trước khi vào hệ thống AI.
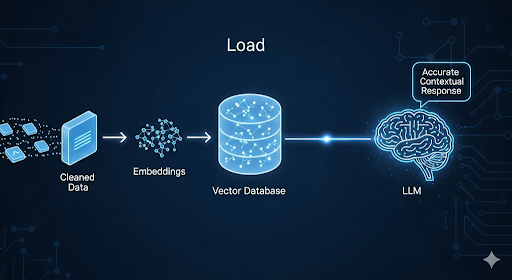
Khi dữ liệu đã sạch và có embedding, bước tiếp theo là đưa vào hạ tầng lưu trữ để AI có thể truy vấn.
Việc áp dụng pipeline ETL vào RAG không chỉ mang ý nghĩa kỹ thuật, mà còn trực tiếp tác động đến độ tin cậy và hiệu suất của hệ thống AI. Dưới đây là những lợi ích nổi bật mà developer và doanh nghiệp có thể nhận được.

Khi dữ liệu đã được chuẩn hóa và index thành vector, quá trình tìm kiếm sẽ diễn ra nhanh chóng và chính xác hơn. Ví dụ, nếu người dùng hỏi “Top 10 khách hàng chi tiêu nhiều nhất quý 2/2025”, hệ thống không cần quét toàn bộ cơ sở dữ liệu thô, mà chỉ cần tìm embedding gần nhất trong vector database.
Một trong những rủi ro lớn khi làm AI là hallucination – AI trả lời sai hoặc tự bịa thông tin. Pipeline ETL giúp:
Một pipeline được thiết kế modular (tách riêng Extract – Transform – Load) cho phép developer:
Điều này giúp hệ thống có khả năng phát triển lâu dài mà không bị phụ thuộc vào một công nghệ cố định.
Khi dữ liệu được chuẩn hóa và AI có thể truy xuất chính xác, doanh nghiệp nhận về những lợi ích rõ rệt:
Việc đồng bộ dữ liệu từ nhiều nguồn về một hệ thống AI thông qua pipeline ETL đơn giản chính là nền móng vững chắc cho các mô hình RAG. Khi dữ liệu được chuẩn hóa và tích hợp hiệu quả, doanh nghiệp không chỉ tối ưu hiệu suất AI mà còn mở rộng khả năng ứng dụng trong bán hàng, marketing và chăm sóc khách hàng.
 Tài liệu kỹ thuật AI Chat
Tài liệu kỹ thuật AI Chat
