Việc quản lý và phân tích lượng dữ liệu khổng lồ trở thành một thách thức lớn đối với các doanh nghiệp. Data Lake (hồ dữ liệu) - một công nghệ lưu trữ dữ liệu mới, giúp giải quyết vấn đề này bằng cách lưu trữ dữ liệu thô ở dạng nguyên bản, dễ dàng truy cập và phân tích. Bài viết này, Bizfly sẽ giúp bạn hiểu rõ Data Lake là gì, vai trò quan trọng của nó trong doanh nghiệp, cách thiết lập và phân biệt giữa Data Lake và Data Warehouse.
Data lake là gì?
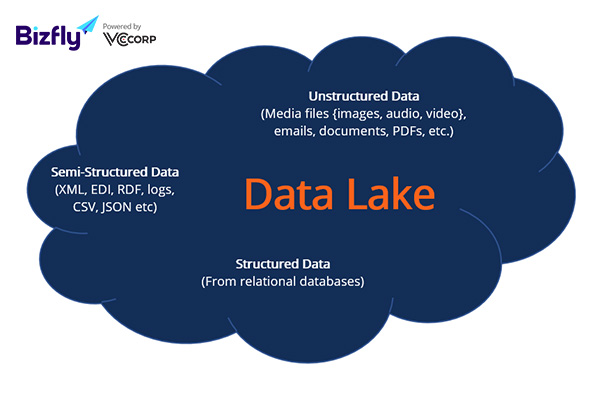
Data Lake (Hồ dữ liệu) là một kho lưu trữ tập trung được thiết kế để lưu trữ, xử lý và bảo mật một lượng lớn dữ liệu đa dạng, bao gồm dữ liệu có cấu trúc (Structured Data), dữ liệu phi cấu trúc (Unstructured Data) và bán cấu trúc. Nó cho phép nhập và lưu trữ dữ liệu ở dạng nguyên bản mà không cần cấu trúc trước. Điều này mang lại sự linh hoạt trong việc hỗ trợ các phân tích khác nhau, bao gồm xử lý dữ liệu lớn, phân tích thời gian thực (Real-time Analytics), học máy và trí tuệ nhân tạo, giúp doanh nghiệp đưa ra quyết định thông minh hơn.
Khái niệm về Data Lake được giới thiệu nhằm giải quyết các thách thức liên quan đến các kho dữ liệu tách biệt và những hạn chế của các kho dữ liệu nhỏ. Bằng cách hợp nhất dữ liệu vào một kho lưu trữ duy nhất, hồ dữ liệu hướng tới việc cung cấp cái nhìn toàn diện hơn về dữ liệu của tổ chức, thúc đẩy phân tích và hiểu biết sâu sắc hơn.
Tuy nhiên, cần lưu ý rằng nếu không được quản lý tốt, hồ dữ liệu có thể trở thành "đầm lầy dữ liệu", nơi dữ liệu bị mất trật tự, thiếu quản trị phù hợp và trở nên khó phân tích. Các thực hành quản lý dữ liệu hiệu quả, bao gồm quản lý siêu dữ liệu, các biện pháp đảm bảo chất lượng dữ liệu và các chính sách quản trị chặt chẽ, là cần thiết để duy trì tính khả dụng và toàn vẹn của hồ dữ liệu.
Data Lake (Hồ dữ liệu) là một kho lưu trữ tập trung được thiết kế để lưu trữ, xử lý và bảo mật một lượng lớn dữ liệu đa dạng
Vai trò của Data Lake với doanh nghiệp
Data Lake đóng vai trò quan trọng trong việc nâng cao hiệu quả hoạt động và khả năng cạnh tranh của doanh nghiệp. Dưới đây là một số lợi ích của Data Lake mang lại:
Thúc đẩy hiệu suất hoạt động: Data Lake cho phép thu thập và phân tích dữ liệu từ nhiều nguồn khác nhau, bao gồm dữ liệu thời gian thực từ các thiết bị IoT. Điều này giúp doanh nghiệp tối ưu hóa quy trình, giảm thiểu chi phí và nâng cao chất lượng công việc.
Cải thiện tương tác với khách hàng: Bằng cách kết nối và phân tích dữ liệu khách hàng từ các hệ thống CRM, nền tảng thương mại điện tử và mạng xã hội, Data Lake giúp doanh nghiệp hiểu rõ hơn về nhu cầu và hành vi của khách hàng. Thông tin này hỗ trợ xây dựng các chiến lược tiếp thị hiệu quả và tăng cường lòng trung thành của khách hàng.
Hỗ trợ đổi mới và nghiên cứu phát triển (R&D): Data Lake cung cấp nền tảng để các nhóm R&D truy cập và phân tích dữ liệu từ nhiều nguồn, giúp kiểm tra giả thuyết, đánh giá kết quả và điều chỉnh chiến lược phát triển sản phẩm hoặc dịch vụ một cách chính xác hơn.
Tiết kiệm chi phí và tăng tính linh hoạt: Với khả năng lưu trữ dữ liệu ở định dạng gốc và hỗ trợ nhiều loại dữ liệu, Data Lake giúp doanh nghiệp tiết kiệm chi phí lưu trữ và tăng tính linh hoạt trong việc truy cập và phân tích dữ liệu.
Hỗ trợ phân tích dữ liệu lớn và thời gian thực: Data Lake cho phép xử lý và phân tích dữ liệu lớn và dữ liệu thời gian thực, cung cấp thông tin kịp thời để hỗ trợ quyết định kinh doanh nhanh chóng và chính xác.
Tuy nhiên, để tận dụng tối đa lợi ích từ Data Lake, doanh nghiệp cần thực hiện các biện pháp quản lý dữ liệu hiệu quả, bao gồm quản lý siêu dữ liệu, đảm bảo chất lượng dữ liệu và thiết lập chính sách quản trị dữ liệu chặt chẽ. Điều này giúp duy trì tính khả dụng và toàn vẹn của dữ liệu, tránh tình trạng "đầm lầy dữ liệu" (data swamp) do quản lý kém.
Data Lake giúp nâng cao hiệu quả hoạt động và khả năng cạnh tranh của doanh nghiệp
Kiến trúc Data Lake
Kiến trúc của Data Lake được thiết kế để lưu trữ và xử lý một lượng lớn dữ liệu từ nhiều nguồn khác nhau, bao gồm dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc. Dưới đây là các thành phần chính trong kiến trúc của Data Lake:
Nguồn dữ liệu (Data Sources): Data Lake có khả năng tích hợp các nguồn dữ liệu đa dạng, bao gồm dữ liệu cấu trúc, không cấu trúc và bán cấu trúc.
Tiếp nhận dữ liệu (Data Ingestion): Quá trình tiếp nhận dữ liệu từ các nguồn khác nhau vào Data Lake có thể được thực hiện theo hai phương pháp chính:
Batch/Scheduled Ingestion: Nhận dữ liệu theo lịch trình định kỳ (hàng ngày, hàng tuần, hàng tháng) hoặc theo nhóm.
Real-time/Stream Ingestion: Nhận dữ liệu theo thời gian thực hoặc luồng dữ liệu liên tục từ các nguồn dữ liệu.
Lưu trữ dữ liệu (Data Storage): Data Lake sử dụng kiến trúc phẳng để lưu trữ dữ liệu, khác với việc lưu trữ theo kích thước và bảng phân cấp ở Data Warehouse. Điều này giúp người dùng linh hoạt hơn trong quá trình quản lý, lưu trữ và sử dụng dữ liệu.
Quản lý siêu dữ liệu (Metadata Management): Quản lý siêu dữ liệu là một thành phần quan trọng trong kiến trúc Data Lake, giúp tổ chức và truy xuất dữ liệu hiệu quả.
Xử lý dữ liệu (Data Processing): Data Lake hỗ trợ các công cụ và nền tảng xử lý dữ liệu mạnh mẽ, cho phép thực hiện các phân tích phức tạp và học máy trên dữ liệu lưu trữ.
Bảo mật và quản trị (Security and Governance): Đảm bảo an toàn và tuân thủ quy định là yếu tố quan trọng trong kiến trúc Data Lake, bao gồm kiểm soát truy cập, mã hóa dữ liệu và theo dõi hoạt động.
Tiêu thụ dữ liệu (Data Consumption): Data Lake cung cấp giao diện và công cụ cho người dùng và ứng dụng để truy xuất và phân tích dữ liệu, hỗ trợ các quyết định kinh doanh dựa trên dữ liệu.
Việc thiết kế và triển khai một Data Lake hiệu quả đòi hỏi sự kết hợp chặt chẽ giữa các thành phần trên, đảm bảo khả năng mở rộng, linh hoạt và bảo mật cho tổ chức.
Các bước triển khai Data lake hiệu quả
Việc triển khai Data Lake hiệu quả đòi hỏi một quy trình cẩn thận và có hệ thống. Dưới đây là các bước quan trọng để triển khai Data Lake thành công:
Xác định mục tiêu và yêu cầu kinh doanh: Trước khi bắt đầu, cần rõ ràng về mục tiêu kinh doanh mà Data Lake sẽ hỗ trợ, như cải thiện phân tích dữ liệu, tối ưu hóa quy trình hoặc phát triển sản phẩm mới. Việc này giúp định hướng thiết kế và triển khai phù hợp.
Lập kế hoạch và thiết kế kiến trúc: Xây dựng kế hoạch chi tiết về cách thức thu thập, lưu trữ và xử lý dữ liệu. Thiết kế kiến trúc Data Lake cần đảm bảo khả năng mở rộng, linh hoạt và tích hợp với các hệ thống hiện có.
Lựa chọn công nghệ và nền tảng phù hợp: Chọn lựa công nghệ và nền tảng lưu trữ phù hợp với nhu cầu và ngân sách của doanh nghiệp, như các giải pháp đám mây hoặc tại chỗ, đảm bảo khả năng mở rộng và tích hợp dễ dàng.
Thu thập và chuẩn bị dữ liệu: Thu thập dữ liệu từ các nguồn khác nhau, bao gồm dữ liệu có cấu trúc và phi cấu trúc. Quá trình này cần đảm bảo dữ liệu được làm sạch, chuẩn hóa và phân loại để dễ dàng truy cập và phân tích sau này.
Thiết lập quản trị dữ liệu và bảo mật: Xây dựng các chính sách quản trị dữ liệu, bao gồm kiểm soát quyền truy cập, mã hóa và tuân thủ các quy định về bảo mật và quyền riêng tư. Điều này đảm bảo dữ liệu được bảo vệ và sử dụng đúng mục đích.
Triển khai và tích hợp hệ thống: Tiến hành triển khai Data Lake theo kế hoạch đã đề ra, tích hợp với các hệ thống và công cụ phân tích dữ liệu hiện có để đảm bảo tính liên tục và hiệu quả trong việc truy cập và sử dụng dữ liệu.
Giám sát và tối ưu hóa: Liên tục giám sát hiệu suất của Data Lake, đánh giá chất lượng dữ liệu và thực hiện các biện pháp tối ưu hóa để cải thiện hiệu quả hoạt động và đáp ứng nhu cầu kinh doanh thay đổi.
Việc tuân thủ các bước trên sẽ giúp doanh nghiệp triển khai Data Lake một cách hiệu quả, tận dụng tối đa giá trị từ dữ liệu và hỗ trợ các quyết định kinh doanh chính xác hơn.
Việc tuân thủ các bước trên sẽ giúp doanh nghiệp triển khai Data Lake một cách hiệu quả
Sự khác biệt giữa Data lake và Data warehouse
Data Lake vs Data Warehouse đều là các kho lưu trữ dữ liệu quan trọng trong doanh nghiệp, nhưng chúng có những điểm khác biệt cơ bản về cấu trúc, mục đích sử dụng và cách thức xử lý dữ liệu. Dưới đây là một số sự khác biệt chính:
Loại dữ liệu lưu trữ:
Data Warehouse: Lưu trữ dữ liệu có cấu trúc, được trích xuất từ các hệ thống giao dịch và ứng dụng chức năng kinh doanh. Dữ liệu trong Data Warehouse thường đã được làm sạch và chuyển đổi để phục vụ cho các mục đích phân tích và báo cáo.
Data Lake: Lưu trữ tất cả các loại dữ liệu, bao gồm dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc. Dữ liệu được lưu trữ ở dạng thô, chưa qua xử lý, cho phép lưu trữ một lượng lớn dữ liệu từ nhiều nguồn khác nhau.
Cấu trúc dữ liệu:
Data Warehouse: Áp dụng phương pháp "Schema on Write", nghĩa là dữ liệu được cấu trúc và chuyển đổi trước khi lưu trữ. Quá trình này đòi hỏi đầu tư thời gian và công sức để phân tích và thiết kế mô hình dữ liệu phù hợp.
Data Lake: Sử dụng phương pháp "Schema on Read", nghĩa là dữ liệu được lưu trữ ở trạng thái nguyên bản và chỉ được cấu trúc khi cần thiết. Điều này giúp tiết kiệm thời gian và chi phí trong quá trình lưu trữ dữ liệu.
Tính linh hoạt và khả năng mở rộng:
Data Warehouse: Do cấu trúc dữ liệu chặt chẽ, việc thay đổi hoặc mở rộng Data Warehouse có thể tốn kém và phức tạp.
Data Lake: Với khả năng lưu trữ dữ liệu ở dạng thô và không có cấu trúc cố định, Data Lake cung cấp tính linh hoạt cao và dễ dàng mở rộng để đáp ứng nhu cầu lưu trữ dữ liệu ngày càng tăng.
Chi phí lưu trữ:
Data Warehouse: Chi phí lưu trữ thường cao hơn do yêu cầu về phần cứng và phần mềm chuyên dụng để xử lý và lưu trữ dữ liệu có cấu trúc.
Data Lake: Chi phí lưu trữ thấp hơn nhờ sử dụng các công nghệ lưu trữ phân tán và chi phí thấp, cho phép lưu trữ lượng lớn dữ liệu mà không tốn kém.
Mục đích sử dụng:
Data Warehouse: Hỗ trợ các hoạt động phân tích và báo cáo kinh doanh truyền thống, cung cấp cái nhìn tổng quan về hiệu suất và tình trạng kinh doanh.
Data Lake: Hỗ trợ các phân tích phức tạp hơn, bao gồm phân tích dữ liệu lớn, học máy và trí tuệ nhân tạo, cho phép khai thác giá trị từ dữ liệu chưa qua xử lý.
Tóm lại, Data Warehouse và Data Lake đều có vai trò quan trọng trong việc quản lý và phân tích dữ liệu doanh nghiệp, nhưng chúng phục vụ các mục đích khác nhau và có cách tiếp cận khác nhau trong việc xử lý và lưu trữ dữ liệu.
Data Warehouse và Data Lake đều có vai trò quan trọng trong việc quản lý và phân tích dữ liệu doanh nghiệp
Thách thức khi triển khai hồ dữ liệu trong doanh nghiệp
Việc triển khai Data Lake mang lại nhiều lợi ích nhưng cũng gặp phải một số thách thức mà các tổ chức cần giải quyết để đảm bảo triển khai thành công. Các thách thức chính bao gồm:
Độ tin cậy của dữ liệu
Đảm bảo tính chính xác và nhất quán của dữ liệu là rất quan trọng. Nếu không có các công cụ phù hợp, Data Lake có thể gặp phải vấn đề về độ tin cậy, khiến cho các nhà khoa học dữ liệu và nhà phân tích gặp khó khăn trong việc tin tưởng vào dữ liệu. Việc triển khai các công cụ bảo đảm chất lượng dữ liệu và các khả năng giao dịch có thể giúp duy trì tính toàn vẹn của dữ liệu.
Quản trị dữ liệu
Việc thiết lập các khuôn khổ quản trị dữ liệu mạnh mẽ là rất cần thiết để quản lý quyền truy cập, bảo mật và tuân thủ. Nếu không có quản trị hiệu quả, Data Lake có thể biến thành "data swamp" (đầm lầy dữ liệu), nơi dữ liệu bị mất tổ chức và khó sử dụng.
Tích hợp dữ liệu
Việc tích hợp dữ liệu từ các nguồn khác nhau với các định dạng và cấu trúc khác nhau có thể rất phức tạp. Data Lake cần phải xử lý cả dữ liệu theo lô và dữ liệu theo thời gian thực một cách hiệu quả, yêu cầu các chiến lược tích hợp nâng cao.
Tối ưu hóa hiệu suất
Đảm bảo rằng Data Lake có thể xử lý khối lượng dữ liệu lớn và các truy vấn phức tạp mà không bị giảm hiệu suất là một thách thức lớn. Việc triển khai các công cụ truy vấn nâng cao và tối ưu hóa lưu trữ dữ liệu có thể giúp cải thiện hiệu suất.
Bảo mật và quyền riêng tư
Việc bảo vệ dữ liệu nhạy cảm trong Data Lake là rất quan trọng. Cần phải triển khai các biện pháp bảo mật nghiêm ngặt và kiểm soát quyền truy cập để ngăn ngừa truy cập trái phép và đảm bảo quyền riêng tư của dữ liệu.
Quản lý chi phí
Mặc dù Data Lake có thể tiết kiệm chi phí, nhưng việc quản lý chi phí lưu trữ và xử lý khi khối lượng dữ liệu ngày càng tăng là rất cần thiết. Việc sử dụng các giải pháp lưu trữ có thể mở rộng và các khung xử lý dữ liệu hiệu quả sẽ giúp kiểm soát chi phí.
Thiếu nhân lực chuyên môn
Việc thiếu hụt các chuyên gia có kinh nghiệm trong việc thiết lập và quản lý Data Lake là một vấn đề. Đầu tư vào đào tạo và phát triển hoặc hợp tác với các nhà cung cấp có kinh nghiệm có thể giúp giải quyết thách thức này.
Việc vượt qua những thách thức này đòi hỏi phải có kế hoạch cẩn thận, chọn lựa công nghệ phù hợp và đội ngũ nhân viên có kỹ năng để đảm bảo triển khai và vận hành Data Lake thành công.
Chọn công nghệ phù hợp và đội ngũ nhân viên có kỹ năng để vận hành Data Lake thành công
Tương lai của Data Lake
Tương lai của Data Lake đang phát triển để đáp ứng nhu cầu ngày càng tăng về quản lý và phân tích dữ liệu hiện đại. Một số xu hướng chính đang định hình tương lai của chúng bao gồm:
Sự hội tụ giữa Data Lake và Data Warehouse:
Ranh giới giữa Data Lake và data warehouses đang ngày càng mờ nhạt.
Các kho dữ liệu (data warehouse) đang tích hợp khả năng xử lý dữ liệu phi cấu trúc, trong khi các Data Lake cũng đang thêm các tính năng truyền thống của data warehouses.
Sự hội tụ này cho phép các tổ chức tận dụng các ưu điểm của cả hai hệ thống, cung cấp một giải pháp quản lý dữ liệu toàn diện hơn.
Xử lý dữ liệu thời gian thực:
Khi các ngành công nghiệp yêu cầu cái nhìn nhanh chóng hơn, các Data Lake đang phát triển để hỗ trợ dòng dữ liệu và xử lý dữ liệu thời gian thực.
Khả năng này cho phép doanh nghiệp đưa ra quyết định kịp thời dựa trên dữ liệu mới nhất có sẵn.
Tích hợp với các công nghệ tiên tiến:
Các Data Lake ngày càng tích hợp với Artificial Intelligence (AI) và Machine Learning (ML).
Sự tích hợp này thúc đẩy phân tích nâng cao, mô hình dự báo và các cái nhìn sâu sắc hơn, giúp tổ chức khai thác giá trị tối đa từ dữ liệu của họ.
Áp dụng kiến trúc đám mây lai (Hybrid Cloud):
Các tổ chức đang áp dụng chiến lược đám mây lai, kết hợp giữa lưu trữ dữ liệu tại chỗ và trên đám mây.
Phương pháp này mang lại sự linh hoạt, khả năng mở rộng và tính hiệu quả về chi phí, cho phép doanh nghiệp tối ưu hóa chiến lược quản lý dữ liệu của mình.
Tăng cường quản trị dữ liệu và bảo mật:
Với khối lượng và độ phức tạp của dữ liệu ngày càng tăng, các biện pháp quản trị dữ liệu và bảo mật mạnh mẽ trở nên quan trọng hơn bao giờ hết.
Việc thực hiện quản lý metadata hiệu quả và kiểm soát quyền truy cập đảm bảo tính toàn vẹn, quyền riêng tư và sự tuân thủ các quy định.
Data Lake mang lại sự linh hoạt và khả năng mở rộng vượt trội cho việc lưu trữ và phân tích dữ liệu thô - Big Data Processing, hỗ trợ doanh nghiệp trong việc khai thác thông tin quan trọng từ nhiều nguồn dữ liệu khác nhau. Việc hiểu rõ về cách thiết lập và phân biệt với Data Warehouse sẽ giúp các doanh nghiệp tối ưu hóa quy trình phân tích dữ liệu và đưa ra các quyết định chiến lược chính xác hơn. Đón đọc thêm các bài viết chuyên môn được Bizfly cập nhật mỗi ngày tại đây.
Nguyễn Hữu Dũng là chuyên gia với hơn 18 năm kinh nghiệm trong ngành công nghệ thông tin, hiện là Giám đốc Sản phẩm tại Bizfly (VCCorp). Tốt nghiệp Đại học Quốc gia Hà Nội, anh phụ trách các giải pháp công nghệ trọng điểm của Bizfly bao gồm Thiết kế Website, BizCRM, Bizfly CDP và BizMobile App, tập trung vào quản lý khách hàng, phân tích dữ liệu và xây dựng hạ tầng số toàn diện cho doanh nghiệp.
Anh Dũng đã dẫn dắt đội ngũ triển khai thành công nhiều dự án lớn cho các tập đoàn và doanh nghiệp trong nhiều lĩnh vực như: Vinfast, Bảo tín Mạnh Hải, Sohaco, Doji... đồng thời thường xuyên chia sẻ kiến thức về chuyển đổi số, quản lý khách hàng và vận hành hệ thống công nghệ hiệu quả
Nhằm giúp các đơn vị giáo dục tìm ra hướng đi phù hợp trong giai đoạn chuyển đổi số và ứng dụng AI, Bizfly VCCorp tổ chức webinar Smart Edu Talk – Xây dựng hệ thống quản lý học viên toàn diện với CRM & AI.
 Về trang chủ Bizfly
Về trang chủ Bizfly
 Đăng nhập
Đăng nhập

 Loading ...
Loading ...
 Nguyễn Hữu Dũng
Nguyễn Hữu Dũng






 Techblog
Techblog

